incrementalLearner
Description
IncrementalMdl = incrementalLearner(Mdl)IncrementalMdl, using the parameters and hyperparameters of the
traditionally trained, Gaussian kernel regression model Mdl. Because
its property values reflect the knowledge gained from Mdl,
IncrementalMdl can predict responses given new observations, and it
is warm, meaning that its predictive performance is tracked.
IncrementalMdl = incrementalLearner(Mdl,Name=Value)IncrementalMdl before its
predictive performance is tracked. For example,
MetricsWarmupPeriod=50,MetricsWindowSize=100 specifies a preliminary
incremental training period of 50 observations before performance metrics are tracked, and
specifies processing 100 observations before updating the window performance metrics.
Examples
Train a kernel regression model by using fitrkernel, and then convert it to an incremental learner.
Load and Preprocess Data
Load the 2015 NYC housing data set. For more details on the data, see NYC Open Data.
load NYCHousing2015Extract the response variable SALEPRICE from the table. For numerical stability, scale SALEPRICE by 1e6.
Y = NYCHousing2015.SALEPRICE/1e6; NYCHousing2015.SALEPRICE = [];
To reduce computational cost for this example, remove the NEIGHBORHOOD column, which contains a categorical variable with 254 categories.
NYCHousing2015.NEIGHBORHOOD = [];
Create dummy variable matrices from the other categorical predictors.
catvars = ["BOROUGH","BUILDINGCLASSCATEGORY"]; dumvarstbl = varfun(@(x)dummyvar(categorical(x)),NYCHousing2015, ... InputVariables=catvars); dumvarmat = table2array(dumvarstbl); NYCHousing2015(:,catvars) = [];
Treat all other numeric variables in the table as predictors of sales price. Concatenate the matrix of dummy variables to the rest of the predictor data.
idxnum = varfun(@isnumeric,NYCHousing2015,OutputFormat="uniform");
X = [dumvarmat NYCHousing2015{:,idxnum}];Train Kernel Regression Model
Fit a kernel regression model to the entire data set.
Mdl = fitrkernel(X,Y)
Mdl =
RegressionKernel
ResponseName: 'Y'
Learner: 'svm'
NumExpansionDimensions: 2048
KernelScale: 1
Lambda: 1.0935e-05
BoxConstraint: 1
Epsilon: 0.0549
Properties, Methods
Mdl is a RegressionKernel model object representing a traditionally trained kernel regression model.
Convert Trained Model
Convert the traditionally trained kernel regression model to a model for incremental learning.
IncrementalMdl = incrementalLearner(Mdl)
IncrementalMdl =
incrementalRegressionKernel
IsWarm: 1
Metrics: [1×2 table]
ResponseTransform: 'none'
NumExpansionDimensions: 2048
KernelScale: 1
Properties, Methods
IncrementalMdl is an incrementalRegressionKernel model object prepared for incremental learning.
The
incrementalLearnerfunction initializes the incremental learner by passing model parameters to it, along with other informationMdlextracted from the training data.IncrementalMdlis warm (IsWarmis1), which means that incremental learning functions can start tracking performance metrics.incrementalRegressionKerneltrains the model using the adaptive scale-invariant solver, whereasfitrkerneltrainedMdlusing the Limited-memory Broyden-Fletcher-Goldfarb-Shanno (LBFGS) solver.
Predict Responses
An incremental learner created from converting a traditionally trained model can generate predictions without further processing.
Predict sales prices for all observations using both models.
ttyfit = predict(Mdl,X); ilyfit = predict(IncrementalMdl,X); compareyfit = norm(ttyfit - ilyfit)
compareyfit = 0
The difference between the fitted values generated by the models is 0.
Use a trained kernel regression model to initialize an incremental learner. Prepare the incremental learner by specifying a metrics warm-up period and a metrics window size.
Load the robot arm data set.
load robotarmFor details on the data set, enter Description at the command line.
Randomly partition the data into 5% and 95% sets: the first set for training a model traditionally, and the second set for incremental learning.
n = numel(ytrain); rng(1) % For reproducibility cvp = cvpartition(n,Holdout=0.95); idxtt = training(cvp); idxil = test(cvp); % 5% set for traditional training Xtt = Xtrain(idxtt,:); Ytt = ytrain(idxtt); % 95% set for incremental learning Xil = Xtrain(idxil,:); Yil = ytrain(idxil);
Fit a kernel regression model to the first set.
TTMdl = fitrkernel(Xtt,Ytt);
Convert the traditionally trained kernel regression model to a model for incremental learning. Specify the following:
A performance metrics warm-up period of 2000 observations.
A metrics window size of 500 observations.
Use of epsilon insensitive loss, MSE, and mean absolute error (MAE) to measure the performance of the model. The software supports epsilon insensitive loss and MSE. Create an anonymous function that measures the absolute error of each new observation. Create a structure array containing the name
MeanAbsoluteErrorand its corresponding function.
maefcn = @(z,zfit)abs(z - zfit); maemetric = struct(MeanAbsoluteError=maefcn); IncrementalMdl = incrementalLearner(TTMdl,MetricsWarmupPeriod=2000,MetricsWindowSize=500, ... Metrics={"epsiloninsensitive","mse",maemetric});
Fit the incremental model to the rest of the data by using the updateMetricsAndFit function. At each iteration:
Simulate a data stream by processing 50 observations at a time.
Overwrite the previous incremental model with a new one fitted to the incoming observations.
Store the cumulative metrics, window metrics, and number of training observations to see how they evolve during incremental learning.
% Preallocation nil = numel(Yil); numObsPerChunk = 50; nchunk = floor(nil/numObsPerChunk); ei = array2table(zeros(nchunk,2),VariableNames=["Cumulative","Window"]); mse = array2table(zeros(nchunk,2),VariableNames=["Cumulative","Window"]); mae = array2table(zeros(nchunk,2),VariableNames=["Cumulative","Window"]); numtrainobs = [IncrementalMdl.NumTrainingObservations; zeros(nchunk+1,1)]; % Incremental fitting for j = 1:nchunk ibegin = min(nil,numObsPerChunk*(j-1) + 1); iend = min(nil,numObsPerChunk*j); idx = ibegin:iend; IncrementalMdl = updateMetricsAndFit(IncrementalMdl,Xil(idx,:),Yil(idx)); ei{j,:} = IncrementalMdl.Metrics{"EpsilonInsensitiveLoss",:}; mse{j,:} = IncrementalMdl.Metrics{"MeanSquaredError",:}; mae{j,:} = IncrementalMdl.Metrics{"MeanAbsoluteError",:}; numtrainobs(j+1) = IncrementalMdl.NumTrainingObservations; end
IncrementalMdl is an incrementalRegressionKernel model object trained on all the data in the stream. During incremental learning and after the model is warmed up, updateMetricsAndFit checks the performance of the model on the incoming observations, and then fits the model to those observations.
Plot a trace plot of the number of training observations and the performance metrics on separate tiles.
t = tiledlayout(4,1); nexttile plot(numtrainobs) xlim([0 nchunk]) xline(IncrementalMdl.MetricsWarmupPeriod/numObsPerChunk,"--") ylabel(["Number of Training","Observations"]) nexttile plot(ei.Variables) xlim([0 nchunk]) ylabel(["Epsilon Insensitive","Loss"]) xline(IncrementalMdl.MetricsWarmupPeriod/numObsPerChunk,"--") legend(ei.Properties.VariableNames,Location="best") nexttile plot(mse.Variables) xlim([0 nchunk]) ylabel("MSE") xline(IncrementalMdl.MetricsWarmupPeriod/numObsPerChunk,"--") nexttile plot(mae.Variables) xlim([0 nchunk]) ylabel("MAE") xline(IncrementalMdl.MetricsWarmupPeriod/numObsPerChunk,"--") xlabel(t,"Iteration")
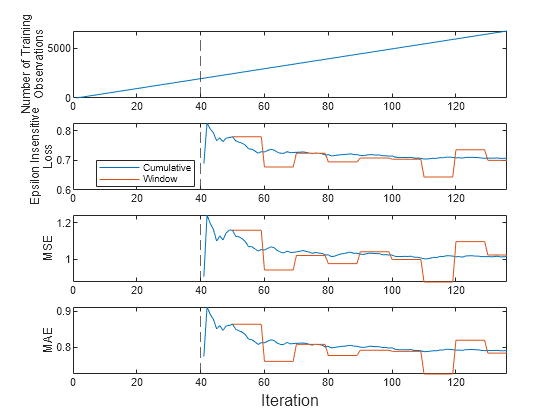
The plot suggests that updateMetricsAndFit does the following:
Fit the model during all incremental learning iterations.
Compute the performance metrics after the metrics warm-up period only.
Compute the cumulative metrics during each iteration.
Compute the window metrics after processing 500 observations.
The default solver for incrementalRegressionKernel is the adaptive scale-invariant solver, which does not require hyperparameter tuning before you fit a model. However, if you specify either the standard stochastic gradient descent (SGD) or average SGD (ASGD) solver instead, you can also specify an estimation period, during which the incremental fitting functions tune the learning rate.
Load and shuffle the 2015 NYC housing data set. For more details on the data, see NYC Open Data.
load NYCHousing2015 rng(1) % For reproducibility n = size(NYCHousing2015,1); shuffidx = randsample(n,n); NYCHousing2015 = NYCHousing2015(shuffidx,:);
Extract the response variable SALEPRICE from the table. For numerical stability, scale SALEPRICE by 1e6.
Y = NYCHousing2015.SALEPRICE/1e6; NYCHousing2015.SALEPRICE = [];
To reduce computational cost for this example, remove the NEIGHBORHOOD column, which contains a categorical variable with 254 categories.
NYCHousing2015.NEIGHBORHOOD = [];
Create dummy variable matrices from the categorical predictors.
catvars = ["BOROUGH","BUILDINGCLASSCATEGORY"]; dumvarstbl = varfun(@(x)dummyvar(categorical(x)),NYCHousing2015, ... InputVariables=catvars); dumvarmat = table2array(dumvarstbl); NYCHousing2015(:,catvars) = [];
Treat all other numeric variables in the table as predictors of sales price. Concatenate the matrix of dummy variables to the rest of the predictor data.
idxnum = varfun(@isnumeric,NYCHousing2015,OutputFormat="uniform");
X = [dumvarmat NYCHousing2015{:,idxnum}];Randomly partition the data into 5% and 95% sets: the first set for training a model traditionally, and the second set for incremental learning.
cvp = cvpartition(n,Holdout=0.95); idxtt = training(cvp); idxil = test(cvp); % 5% set for traditional training Xtt = X(idxtt,:); Ytt = Y(idxtt); % 95% set for incremental learning Xil = X(idxil,:); Yil = Y(idxil);
Fit a kernel regression model to 5% of the data.
Mdl = fitrkernel(Xtt,Ytt);
Convert the traditionally trained kernel regression model to a model for incremental learning. Specify the standard SGD solver and an estimation period of 2e4 observations (the default is 1000 when a learning rate is required).
IncrementalMdl = incrementalLearner(Mdl,Solver="sgd",EstimationPeriod=2e4);IncrementalMdl is an incrementalRegressionKernel model object configured for incremental learning.
Fit the incremental model to the rest of the data by using the fit function. At each iteration:
Simulate a data stream by processing 10 observations at a time.
Overwrite the previous incremental model with a new one fitted to the incoming observations.
Store the initial learning rate and number of training observations to see how they evolve during training.
% Preallocation nil = numel(Yil); numObsPerChunk = 10; nchunk = floor(nil/numObsPerChunk); learnrate = [zeros(nchunk,1)]; numtrainobs = [zeros(nchunk,1)]; % Incremental fitting for j = 1:nchunk ibegin = min(nil,numObsPerChunk*(j-1) + 1); iend = min(nil,numObsPerChunk*j); idx = ibegin:iend; IncrementalMdl = fit(IncrementalMdl,Xil(idx,:),Yil(idx)); learnrate(j) = IncrementalMdl.SolverOptions.LearnRate; numtrainobs(j) = IncrementalMdl.NumTrainingObservations; end
IncrementalMdl is an incrementalRegressionKernel model object trained on all the data in the stream.
Plot a trace plot of the number of training observations and the initial learning rate on separate tiles.
t = tiledlayout(2,1); nexttile plot(numtrainobs) xlim([0 nchunk]) xline(IncrementalMdl.EstimationPeriod/numObsPerChunk,"-."); ylabel("Number of Training Observations") nexttile plot(learnrate) xlim([0 nchunk]) ylabel("Initial Learning Rate") xline(IncrementalMdl.EstimationPeriod/numObsPerChunk,"-."); xlabel(t,"Iteration")
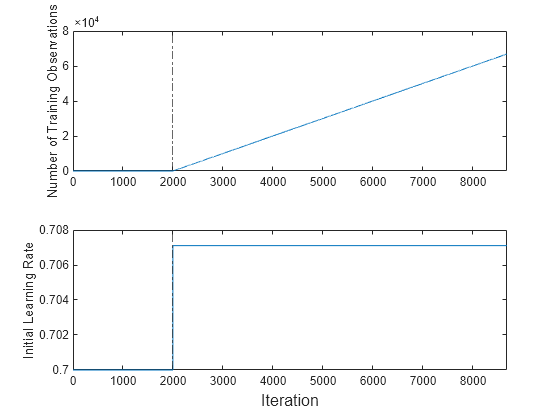
The plot suggests that fit does not fit the model to the streaming data during the estimation period. The initial learning rate jumps from 0.7 to its autotuned value after the estimation period. During training, the software uses a learning rate that gradually decays from the initial value specified in the LearnRateSchedule property of IncrementalMdl.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
References
Version History
Introduced in R2022a