vggish
(Not recommended) VGGish neural network
vggish is not recommended. Use the audioPretrainedNetwork function instead.
Syntax
Description
Examples
Download and unzip the Audio Toolbox™ model for VGGish.
Type vggish at the Command Window. If the Audio Toolbox model for VGGish is not installed, then the function provides a link to the location of the network weights. To download the model, click the link. Unzip the file to a location on the MATLAB path.
Alternatively, execute these commands to download and unzip the VGGish model to your temporary directory.
downloadFolder = fullfile(tempdir,'VGGishDownload'); loc = websave(downloadFolder,'https://ssd.mathworks.com/supportfiles/audio/vggish.zip'); VGGishLocation = tempdir; unzip(loc,VGGishLocation) addpath(fullfile(VGGishLocation,'vggish'))
Check that the installation is successful by typing vggish at the Command Window. If the network is installed, then the function returns a SeriesNetwork (Deep Learning Toolbox) object.
vggish
ans =
SeriesNetwork with properties:
Layers: [24×1 nnet.cnn.layer.Layer]
InputNames: {'InputBatch'}
OutputNames: {'regressionoutput'}
Load a pretrained VGGish convolutional neural network and examine the layers and classes.
Use vggish to load the pretrained VGGish network. The output net is a SeriesNetwork (Deep Learning Toolbox) object.
net = vggish
net =
SeriesNetwork with properties:
Layers: [24×1 nnet.cnn.layer.Layer]
InputNames: {'InputBatch'}
OutputNames: {'regressionoutput'}
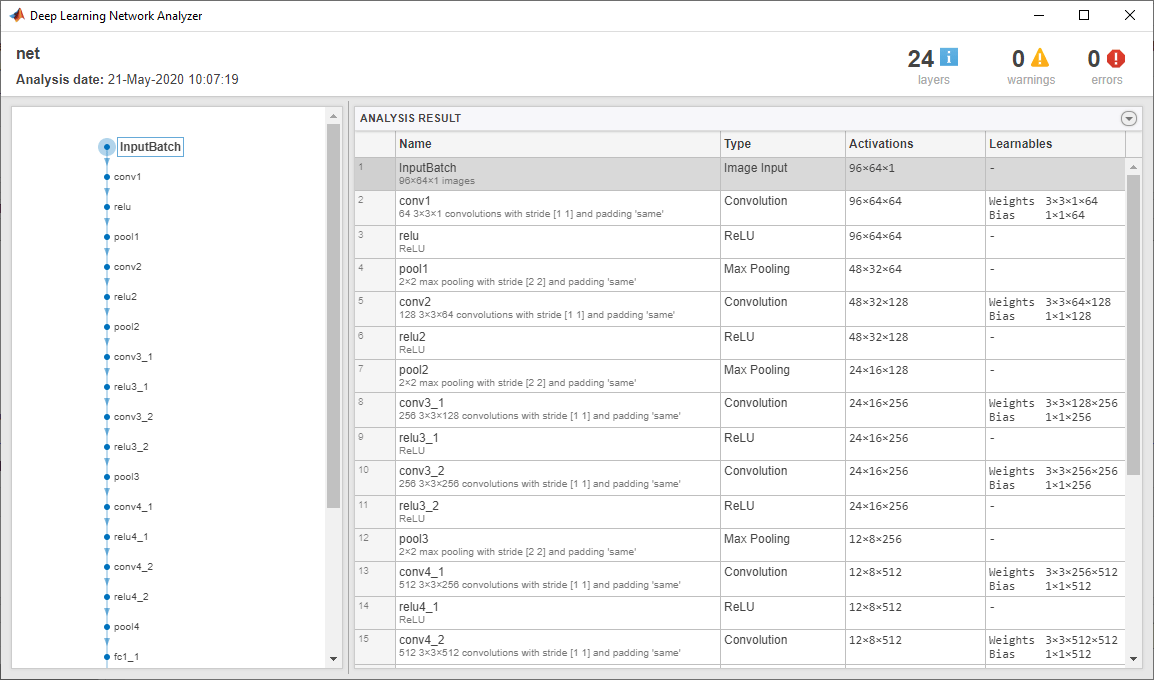
View the network architecture using the Layers property. The network has 24 layers. There are nine layers with learnable weights, of which six are convolutional layers and three are fully connected layers.
net.Layers
ans =
24×1 Layer array with layers:
1 'InputBatch' Image Input 96×64×1 images
2 'conv1' Convolution 64 3×3×1 convolutions with stride [1 1] and padding 'same'
3 'relu' ReLU ReLU
4 'pool1' Max Pooling 2×2 max pooling with stride [2 2] and padding 'same'
5 'conv2' Convolution 128 3×3×64 convolutions with stride [1 1] and padding 'same'
6 'relu2' ReLU ReLU
7 'pool2' Max Pooling 2×2 max pooling with stride [2 2] and padding 'same'
8 'conv3_1' Convolution 256 3×3×128 convolutions with stride [1 1] and padding 'same'
9 'relu3_1' ReLU ReLU
10 'conv3_2' Convolution 256 3×3×256 convolutions with stride [1 1] and padding 'same'
11 'relu3_2' ReLU ReLU
12 'pool3' Max Pooling 2×2 max pooling with stride [2 2] and padding 'same'
13 'conv4_1' Convolution 512 3×3×256 convolutions with stride [1 1] and padding 'same'
14 'relu4_1' ReLU ReLU
15 'conv4_2' Convolution 512 3×3×512 convolutions with stride [1 1] and padding 'same'
16 'relu4_2' ReLU ReLU
17 'pool4' Max Pooling 2×2 max pooling with stride [2 2] and padding 'same'
18 'fc1_1' Fully Connected 4096 fully connected layer
19 'relu5_1' ReLU ReLU
20 'fc1_2' Fully Connected 4096 fully connected layer
21 'relu5_2' ReLU ReLU
22 'fc2' Fully Connected 128 fully connected layer
23 'EmbeddingBatch' ReLU ReLU
24 'regressionoutput' Regression Output mean-squared-error
Use analyzeNetwork (Deep Learning Toolbox) to visually explore the network.
analyzeNetwork(net)
Read in an audio signal to extract feature embeddings from it.
[audioIn,fs] = audioread( "Ambiance-16-44p1-mono-12secs.wav");
"Ambiance-16-44p1-mono-12secs.wav");Plot and listen to the audio signal.
t = (0:numel(audioIn)-1)/fs; plot(t,audioIn) xlabel("Time (s)") ylabel("Ampltiude") axis tight
sound(audioIn,fs)
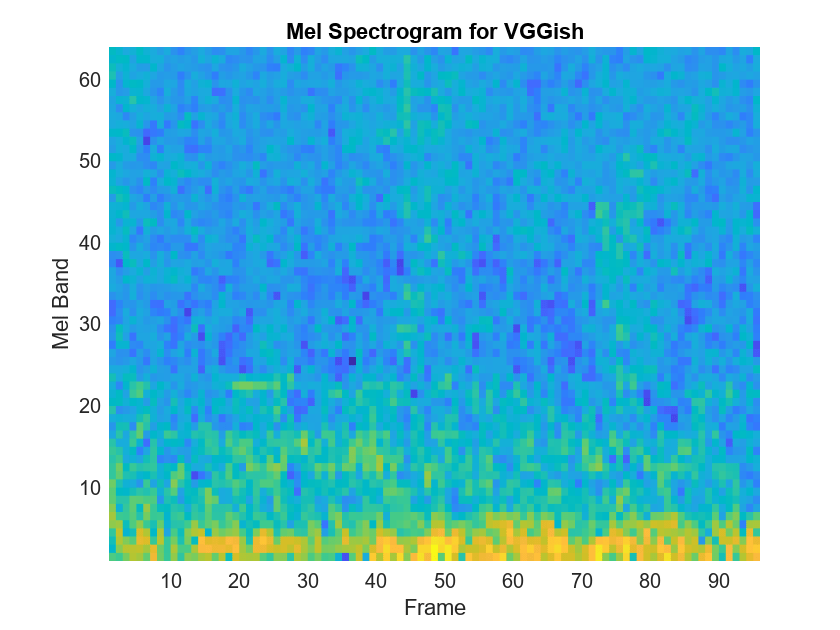
VGGish requires you to preprocess the audio signal to match the input format used to train the network. The preprocesssing steps include resampling the audio signal and computing an array of mel spectrograms. To learn more about mel spectrograms, see melSpectrogram. Use vggishPreprocess to preprocess the signal and extract the mel spectrograms to be passed to VGGish. Visualize one of these spectrograms chosen at random.
spectrograms = vggishPreprocess(audioIn,fs); arbitrarySpect = spectrograms(:,:,1,randi(size(spectrograms,4))); surf(arbitrarySpect,EdgeColor="none") view(90,-90) xlabel("Mel Band") ylabel("Frame") title("Mel Spectrogram for VGGish") axis tight
Create a VGGish neural network using the audioPretrainedNetwork function.
net = audioPretrainedNetwork("vggish");Call predict with the network on the preprocessed mel spectrogram images to extract feature embeddings. The feature embeddings are returned as a numFrames-by-128 matrix, where numFrames is the number of individual spectrograms and 128 is the number of elements in each feature vector.
features = predict(net,spectrograms); [numFrames,numFeatures] = size(features)
numFrames = 24
numFeatures = 128
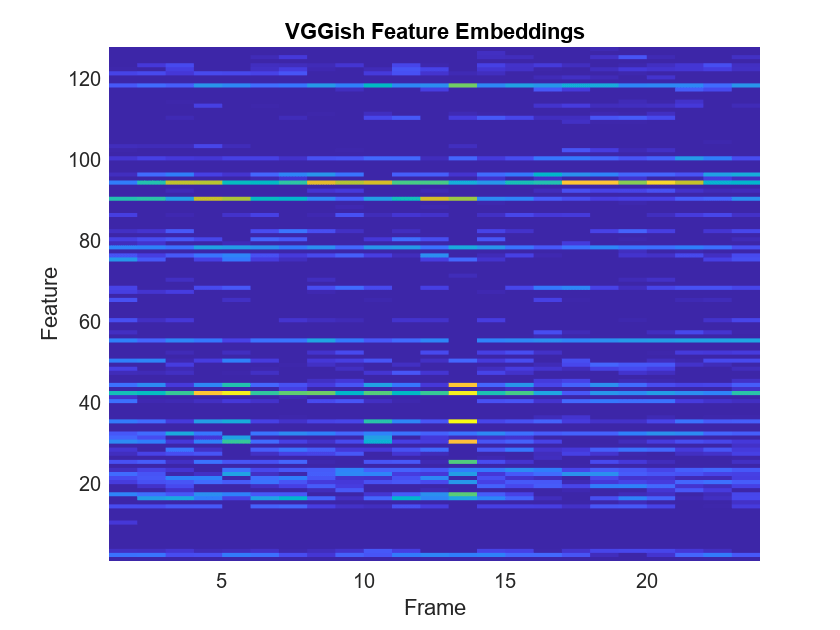
Visualize the VGGish feature embeddings.
surf(features,EdgeColor="none") view([90 -90]) xlabel("Feature") ylabel("Frame") title("VGGish Feature Embeddings") axis tight
In this example, you transfer the learning in the VGGish regression model to an audio classification task.
Download and unzip the environmental sound classification data set. This data set consists of recordings labeled as one of 10 different audio sound classes (ESC-10).
downloadFolder = matlab.internal.examples.downloadSupportFile("audio","ESC-10.zip"); unzip(downloadFolder,tempdir) dataLocation = fullfile(tempdir,"ESC-10");
Create an audioDatastore object to manage the data and split it into train and validation sets. Call countEachLabel to display the distribution of sound classes and the number of unique labels.
ads = audioDatastore(dataLocation,IncludeSubfolders=true,LabelSource="foldernames");
labelTable = countEachLabel(ads)labelTable=10×2 table
chainsaw 40
clock_tick 40
crackling_fire 40
crying_baby 40
dog 40
helicopter 40
rain 40
rooster 38
sea_waves 40
sneezing 40
Determine the total number of classes and their names.
numClasses = height(labelTable); classNames = unique(ads.Labels);
Call splitEachLabel to split the data set into train and validation sets. Inspect the distribution of labels in the training and validation sets.
[adsTrain, adsValidation] = splitEachLabel(ads,0.8); countEachLabel(adsTrain)
ans=10×2 table
chainsaw 32
clock_tick 32
crackling_fire 32
crying_baby 32
dog 32
helicopter 32
rain 32
rooster 30
sea_waves 32
sneezing 32
countEachLabel(adsValidation)
ans=10×2 table
chainsaw 8
clock_tick 8
crackling_fire 8
crying_baby 8
dog 8
helicopter 8
rain 8
rooster 8
sea_waves 8
sneezing 8
The VGGish network expects audio to be preprocessed into log mel spectrograms. Use vggishPreprocess to extract the spectrograms from the train set. There are multiple spectrograms for each audio signal. Replicate the labels so that they are in one-to-one correspondence with the spectrograms.
overlapPercentage =75; trainFeatures = []; trainLabels = []; while hasdata(adsTrain) [audioIn,fileInfo] = read(adsTrain); features = vggishPreprocess(audioIn,fileInfo.SampleRate,OverlapPercentage=overlapPercentage); numSpectrograms = size(features,4); trainFeatures = cat(4,trainFeatures,features); trainLabels = cat(2,trainLabels,repelem(fileInfo.Label,numSpectrograms)); end
Extract spectrograms from the validation set and replicate the labels.
validationFeatures = []; validationLabels = []; segmentsPerFile = zeros(numel(adsValidation.Files), 1); idx = 1; while hasdata(adsValidation) [audioIn,fileInfo] = read(adsValidation); features = vggishPreprocess(audioIn,fileInfo.SampleRate,OverlapPercentage=overlapPercentage); numSpectrograms = size(features,4); validationFeatures = cat(4,validationFeatures,features); validationLabels = cat(2,validationLabels,repelem(fileInfo.Label,numSpectrograms)); segmentsPerFile(idx) = numSpectrograms; idx = idx + 1; end
Load the VGGish model and using audioPretrainedNetwork.
net = audioPretrainedNetwork("vggish");Use addLayers (Deep Learning Toolbox) to add a fullyConnectedLayer (Deep Learning Toolbox) and a softmaxLayer (Deep Learning Toolbox) to the network. Set the WeightLearnRateFactor and BiasLearnRateFactor of the new fully connected layer to 10 so that learning is faster in the new layer than in the transferred layers.
net = addLayers(net,[ ... fullyConnectedLayer(numClasses,Name="FCFinal",WeightLearnRateFactor=10,BiasLearnRateFactor=10) softmaxLayer(Name="softmax")]);
Use connectLayers (Deep Learning Toolbox) to append the fully connected and softmax layers to the network.
net = connectLayers(net,"EmbeddingBatch","FCFinal");
To define training options, use trainingOptions (Deep Learning Toolbox).
miniBatchSize = 128; options = trainingOptions("adam", ... MaxEpochs=5, ... MiniBatchSize=miniBatchSize, ... Shuffle="every-epoch", ... ValidationData={validationFeatures,validationLabels'}, ... ValidationFrequency=50, ... LearnRateSchedule="piecewise", ... LearnRateDropFactor=0.5, ... LearnRateDropPeriod=2, ... OutputNetwork="best-validation-loss", ... Verbose=false, ... Plots="training-progress",... Metrics="accuracy");
To train the network, use trainnet.
[trainedNet,netInfo] = trainnet(trainFeatures,trainLabels',net,"crossentropy",options);![]()
Each audio file was split into several segments to feed into the VGGish network. Combine the predictions for each file in the validation set using a majority-rule decision.
scores = predict(trainedNet,validationFeatures); validationPredictions = scores2label(scores,classNames); idx = 1; validationPredictionsPerFile = categorical; for ii = 1:numel(adsValidation.Files) validationPredictionsPerFile(ii,1) = mode(validationPredictions(idx:idx+segmentsPerFile(ii)-1)); idx = idx + segmentsPerFile(ii); end
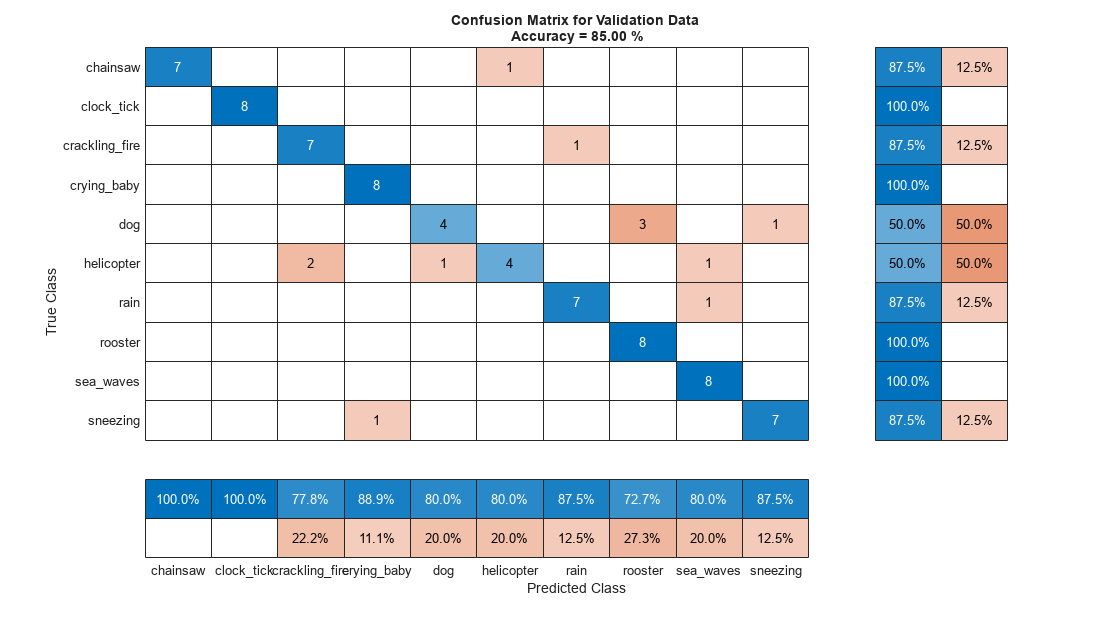
Use confusionchart (Deep Learning Toolbox) to evaluate the performance of the network on the validation set.
figure(Units="normalized",Position=[0.2 0.2 0.5 0.5]); confusionchart(adsValidation.Labels,validationPredictionsPerFile, ... Title=sprintf("Confusion Matrix for Validation Data \nAccuracy = %0.2f %%",mean(validationPredictionsPerFile==adsValidation.Labels)*100), ... ColumnSummary="column-normalized", ... RowSummary="row-normalized")
Output Arguments
References
[1] Gemmeke, Jort F., Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. 2017. “Audio Set: An Ontology and Human-Labeled Dataset for Audio Events.” In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 776–80. New Orleans, LA: IEEE. https://doi.org/10.1109/ICASSP.2017.7952261.
[2] Hershey, Shawn, Sourish Chaudhuri, Daniel P. W. Ellis, Jort F. Gemmeke, Aren Jansen, R. Channing Moore, Manoj Plakal, et al. 2017. “CNN Architectures for Large-Scale Audio Classification.” In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 131–35. New Orleans, LA: IEEE. https://doi.org/10.1109/ICASSP.2017.7952132.
Extended Capabilities
Version History
Introduced in R2020b