fitsemiself
Label data using semi-supervised self-training method
Syntax
Description
fitsemiself creates a semi-supervised self-training model
given labeled data, labels, and unlabeled data. The returned model contains the fitted labels
for the unlabeled data and the corresponding scores. This model can also predict labels for
unseen data using the predict object function. For more information on
the labeling algorithm, see Algorithms.
Mdl = fitsemiself(Tbl,ResponseVarName,UnlabeledTbl)Tbl, where
Tbl.ResponseVarName contains the labels for the labeled data, and
returns fitted labels for the unlabeled data in UnlabeledTbl. The
function stores the fitted labels and the corresponding scores in the
FittedLabels and LabelScores properties of the
object Mdl, respectively.
Mdl = fitsemiself(Tbl,formula,UnlabeledTbl)formula to specify the response variable (vector of labels) and
the predictor variables to use among the variables in Tbl. The
function uses these variables to label the data in
UnlabeledTbl.
Mdl = fitsemiself(Tbl,Y,UnlabeledTbl)Tbl and the labels in
Y to label the data in UnlabeledTbl.
Mdl = fitsemiself(X,Y,UnlabeledX)X and the labels in Y
to label the data in UnlabeledX.
Mdl = fitsemiself(___,Name,Value)
Examples
Fit labels to unlabeled data by using a semi-supervised self-training method.
Randomly generate 60 observations of labeled data, with 20 observations in each of three classes.
rng('default') % For reproducibility labeledX = [randn(20,2)*0.25 + ones(20,2); randn(20,2)*0.25 - ones(20,2); randn(20,2)*0.5]; Y = [ones(20,1); ones(20,1)*2; ones(20,1)*3];
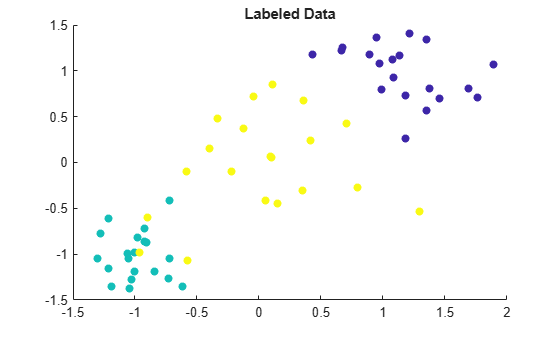
Visualize the labeled data by using a scatter plot. Observations in the same class have the same color. Notice that the data is split into three clusters with very little overlap.
scatter(labeledX(:,1),labeledX(:,2),[],Y,'filled') title('Labeled Data')
Randomly generate 300 additional observations of unlabeled data, with 100 observations per class. For the purposes of validation, keep track of the true labels for the unlabeled data.
unlabeledX = [randn(100,2)*0.25 + ones(100,2);
randn(100,2)*0.25 - ones(100,2);
randn(100,2)*0.5];
trueLabels = [ones(100,1); ones(100,1)*2; ones(100,1)*3];Fit labels to the unlabeled data by using a semi-supervised self-training method. The function fitsemiself returns a SemiSupervisedSelfTrainingModel object whose FittedLabels property contains the fitted labels for the unlabeled data and whose LabelScores property contains the associated label scores.
Mdl = fitsemiself(labeledX,Y,unlabeledX)
Mdl =
SemiSupervisedSelfTrainingModel with properties:
FittedLabels: [300×1 double]
LabelScores: [300×3 double]
ClassNames: [1 2 3]
ResponseName: 'Y'
CategoricalPredictors: []
Learner: [1×1 classreg.learning.classif.CompactClassificationECOC]
Properties, Methods
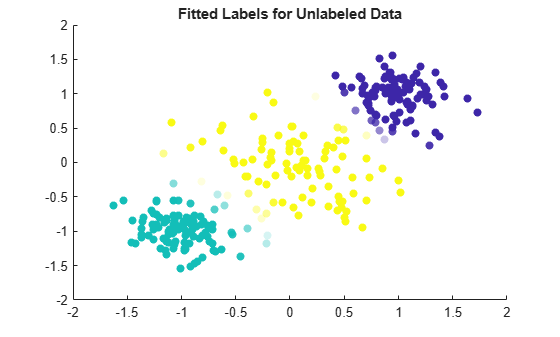
Visualize the fitted label results by using a scatter plot. Use the fitted labels to set the color of the observations, and use the maximum label scores to set the transparency of the observations. Observations with less transparency are labeled with greater confidence. Notice that observations that lie closer to the cluster boundaries are labeled with more uncertainty.
maxLabelScores = max(Mdl.LabelScores,[],2); rescaledScores = rescale(maxLabelScores,0.05,0.95); scatter(unlabeledX(:,1),unlabeledX(:,2),[],Mdl.FittedLabels,'filled', ... 'MarkerFaceAlpha','flat','AlphaData',rescaledScores); title('Fitted Labels for Unlabeled Data')
Determine the accuracy of the labeling by using the true labels for the unlabeled data.
numWrongLabels = sum(trueLabels ~= Mdl.FittedLabels)
numWrongLabels = 7
Only 8 of the 300 observations in unlabeledX are mislabeled.
Fit labels to unlabeled data by using a semi-supervised self-training method. Specify the type of learner used to fit the labels.
Load the carsmall data set. Create a table from the variables Acceleration, Displacement, and so on. For each observation, or row in the table, treat the Cylinders value as the label for that observation.
load carsmall
Tbl = table(Acceleration,Displacement,Horsepower,Weight,Cylinders);Suppose only 20% of the observations are labeled. To recreate this scenario, randomly sample 20 labeled observations and store them in the table unlabeledTbl. Remove the label from the rest of the observations and store them in the table unlabeledTbl. To verify the accuracy of the label fitting at the end of the example, retain the true labels for the unlabeled data in the variable trueLabels.
rng('default') % For reproducibility of the sampling [labeledTbl,Idx] = datasample(Tbl,20,'Replace',false); unlabeledTbl = Tbl; unlabeledTbl(Idx,:) = []; trueLabels = unlabeledTbl.Cylinders; unlabeledTbl.Cylinders = [];
Fit labels to the unlabeled data by using a semi-supervised self-training method. Use a multiclass SVM (ECOC) model to iteratively label the unlabeled observations. Specify to standardize the numeric predictors and use a linear kernel function for the SVM binary learners. The function fitsemiself returns an object whose FittedLabels property contains the fitted labels for the unlabeled data.
Mdl = fitsemiself(labeledTbl,'Cylinders',unlabeledTbl, ... 'Learner',templateECOC('Learner',templateSVM('Standardize',true, ... 'KernelFunction','linear'))); fittedLabels = Mdl.FittedLabels;
Identify the observations that are incorrectly labeled by comparing the stored true labels for the unlabeled data to the fitted labels returned by the semi-supervised self-training method.
wrongIdx = (trueLabels ~= fittedLabels); wrongTbl = unlabeledTbl(wrongIdx,:);
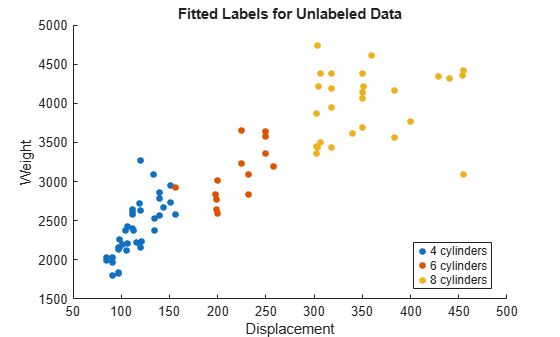
Visualize the fitted label results for the unlabeled data. Mislabeled observations are circled in the plot.
gscatter(unlabeledTbl.Displacement,unlabeledTbl.Weight, ... fittedLabels) hold on plot(wrongTbl.Displacement,wrongTbl.Weight, ... 'ko','MarkerSize',8) xlabel('Displacement') ylabel('Weight') legend('4 cylinders','6 cylinders','8 cylinders') title('Fitted Labels for Unlabeled Data') hold off
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
The algorithm begins by training a user-specified classifier
(Learner), first trained on the labeled data alone, and then uses that
classifier to make label predictions for the unlabeled data. Next, the algorithm provides
scores for the predictions, and then treats the predictions as true labels for the next
training cycle of the classifier if the scores are above a threshold
(ScoreThreshold). This process repeats until the label predictions
converge or the iteration limit (IterationLimit) is reached.
References
[1] Abney, Steven. “Understanding the Yarowsky Algorithm.” Computational Linguistics 30, no. 3 (September 2004): 365–95. https://doi.org/10.1162/0891201041850876.
[2] Yarowsky, David. “Unsupervised Word Sense Disambiguation Rivaling Supervised Methods.” Proceedings of the 33rd Annual Meeting of the Association for Computational Linguistics, 189–96. Cambridge, Massachusetts: Association for Computational Linguistics, 1995. https://doi.org/10.3115/981658.981684.
Version History
Introduced in R2020b