DaviesBouldinEvaluation
Davies-Bouldin criterion clustering evaluation object
Description
DaviesBouldinEvaluation is an object consisting of sample data
(X), clustering data (OptimalY), and Davies-Bouldin
criterion values (CriterionValues) used to
evaluate the optimal number of clusters (OptimalK). The Davies-Bouldin
criterion is based on a ratio of within-cluster and between-cluster distances. The optimal
clustering solution has the smallest Davies-Bouldin index value. For more information, see
Davies-Bouldin Criterion.
Creation
Create a Davies-Bouldin criterion clustering evaluation object by using the evalclusters function and specifying the criterion as
"DaviesBouldin".
You can then use compact to create a compact version of the
Davies-Bouldin criterion clustering evaluation object. The function removes the contents of
the properties X, OptimalY, and
Missing.
Properties
Object Functions
Examples
Evaluate the optimal number of clusters using the Davies-Bouldin clustering evaluation criterion.
Generate sample data containing random numbers from three multivariate distributions with different parameter values.
rng("default") % For reproducibility n = 200; mu1 = [2 2]; sigma1 = [0.9 -0.0255; -0.0255 0.9]; mu2 = [5 5]; sigma2 = [0.5 0; 0 0.3]; mu3 = [-2 -2]; sigma3 = [1 0; 0 0.9]; X = [mvnrnd(mu1,sigma1,n); ... mvnrnd(mu2,sigma2,n); ... mvnrnd(mu3,sigma3,n)];
Evaluate the optimal number of clusters using the Davies-Bouldin criterion. Cluster the data using kmeans.
evaluation = evalclusters(X,"kmeans","DaviesBouldin","KList",1:6)
evaluation =
DaviesBouldinEvaluation with properties:
NumObservations: 600
InspectedK: [1 2 3 4 5 6]
CriterionValues: [NaN 0.4663 0.4454 0.8316 1.0444 0.9236]
OptimalK: 3
Properties, Methods
The OptimalK value indicates that, based on the Davies-Bouldin criterion, the optimal number of clusters is three.
Plot the Davies-Bouldin criterion values for each number of clusters tested.
plot(evaluation)
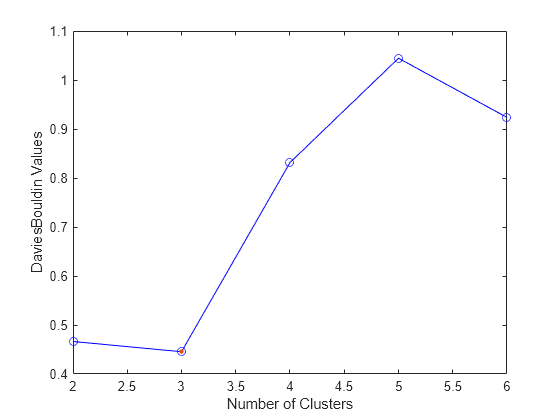
The plot shows that the lowest Davies-Bouldin value occurs at three clusters, suggesting that the optimal number of clusters is three.
Create a grouped scatter plot to visually examine the suggested clusters.
clusters = evaluation.OptimalY;
gscatter(X(:,1),X(:,2),clusters,[],"xod")
The plot shows three distinct clusters within the data: cluster 1 in the lower-left corner, cluster 2 in the upper-right corner, and cluster 3 near the center of the plot.
More About
References
[1] Davies, D. L., and D. W. Bouldin. “A Cluster Separation Measure.” IEEE Transactions on Pattern Analysis and Machine Intelligence. Vol. PAMI-1, No. 2, 1979, pp. 224–227.
Version History
Introduced in R2013b