gmdistribution
Create Gaussian mixture model
Description
A gmdistribution object stores a Gaussian mixture
distribution, also called a Gaussian mixture model (GMM), which is a multivariate
distribution that consists of multivariate Gaussian distribution components. Each
component is defined by its mean and covariance. The mixture is defined by a vector of
mixing proportions, where each mixing proportion represents the fraction of the
population described by a corresponding component.
Creation
You can create a gmdistribution model object in two ways.
Use the
gmdistributionfunction (described here) to create agmdistributionmodel object by specifying the distribution parameters.Use the
fitgmdistfunction to fit agmdistributionmodel object to data given a fixed number of components.
Description
Input Arguments
Properties
Object Functions
cdf | Cumulative distribution function for Gaussian mixture distribution |
cluster | Construct clusters from Gaussian mixture distribution |
mahal | Mahalanobis distance to Gaussian mixture component |
pdf | Probability density function for Gaussian mixture distribution |
posterior | Posterior probability of Gaussian mixture component |
random | Random variate from Gaussian mixture distribution |
Examples
Create a two-component bivariate Gaussian mixture distribution by using the gmdistribution function.
Define the distribution parameters (means and covariances) of two bivariate Gaussian mixture components.
mu = [1 2;-3 -5];
sigma = cat(3,[2 .5],[1 1]) % 1-by-2-by-2 arraysigma =
sigma(:,:,1) =
2.0000 0.5000
sigma(:,:,2) =
1 1
The cat function concatenates the covariances along the third array dimension. The defined covariance matrices are diagonal matrices. sigma(1,:,i) contains the diagonal elements of the covariance matrix of component i.
Create a gmdistribution object. By default, the gmdistribution function creates an equal proportion mixture.
gm = gmdistribution(mu,sigma)
gm = Gaussian mixture distribution with 2 components in 2 dimensions Component 1: Mixing proportion: 0.500000 Mean: 1 2 Component 2: Mixing proportion: 0.500000 Mean: -3 -5
List the properties of the gm object.
properties(gm)
Properties for class gmdistribution:
NumVariables
DistributionName
NumComponents
ComponentProportion
SharedCovariance
NumIterations
RegularizationValue
NegativeLogLikelihood
CovarianceType
mu
Sigma
AIC
BIC
Converged
ProbabilityTolerance
You can access these properties by using dot notation. For example, access the ComponentProportion property, which represents the mixing proportions of mixture components.
gm.ComponentProportion
ans = 1×2
0.5000 0.5000
A gmdistribution object has properties that apply only to a fitted object. The fitted object properties are AIC, BIC, Converged, NegativeLogLikelihood, NumIterations, ProbabilityTolerance, and RegularizationValue. The values of the fitted object properties are empty if you create an object by using the gmdistribution function and specifying distribution parameters. For example, access the NegativeLogLikelihood property by using dot notation.
gm.NegativeLogLikelihood
ans =
[]
After you create a gmdistribution object, you can use the object functions. Use cdf and pdf to compute the values of the cumulative distribution function (cdf) and the probability density function (pdf). Use random to generate random vectors. Use cluster, mahal, and posterior for cluster analysis.
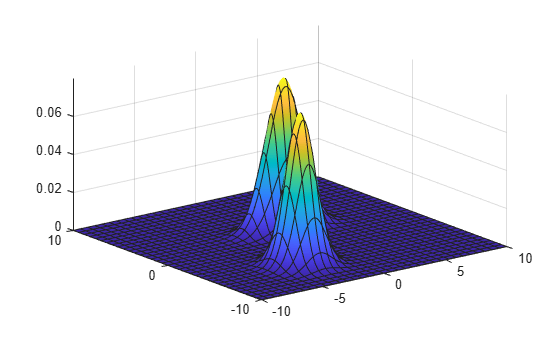
Visualize the object by using pdf and fsurf.
gmPDF = @(x,y) arrayfun(@(x0,y0) pdf(gm,[x0 y0]),x,y); fsurf(gmPDF,[-10 10])
Generate random variates that follow a mixture of two bivariate Gaussian distributions by using the mvnrnd function. Fit a Gaussian mixture model (GMM) to the generated data by using the fitgmdist function.
Define the distribution parameters (means and covariances) of two bivariate Gaussian mixture components.
mu1 = [1 2]; % Mean of the 1st component sigma1 = [2 0; 0 .5]; % Covariance of the 1st component mu2 = [-3 -5]; % Mean of the 2nd component sigma2 = [1 0; 0 1]; % Covariance of the 2nd component
Generate an equal number of random variates from each component, and combine the two sets of random variates.
rng('default') % For reproducibility r1 = mvnrnd(mu1,sigma1,1000); r2 = mvnrnd(mu2,sigma2,1000); X = [r1; r2];
The combined data set X contains random variates following a mixture of two bivariate Gaussian distributions.
Fit a two-component GMM to X.
gm = fitgmdist(X,2)
gm = Gaussian mixture distribution with 2 components in 2 dimensions Component 1: Mixing proportion: 0.500000 Mean: -2.9617 -4.9727 Component 2: Mixing proportion: 0.500000 Mean: 0.9539 2.0261
List the properties of the gm object.
properties(gm)
Properties for class gmdistribution:
NumVariables
DistributionName
NumComponents
ComponentProportion
SharedCovariance
NumIterations
RegularizationValue
NegativeLogLikelihood
CovarianceType
mu
Sigma
AIC
BIC
Converged
ProbabilityTolerance
You can access these properties by using dot notation. For example, access the NegativeLogLikelihood property, which represents the negative loglikelihood of the data X given the fitted model.
gm.NegativeLogLikelihood
ans = 7.0584e+03
After you create a gmdistribution object, you can use the object functions. Use cdf and pdf to compute the values of the cumulative distribution function (cdf) and the probability density function (pdf). Use random to generate random variates. Use cluster, mahal, and posterior for cluster analysis.
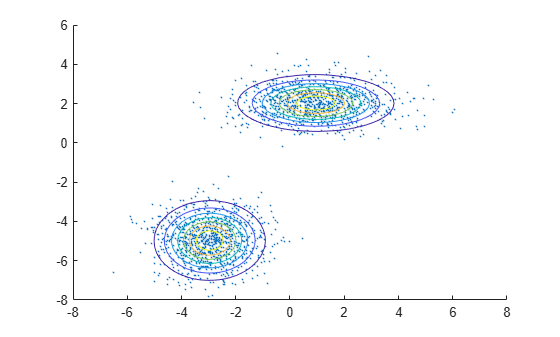
Plot X by using scatter. Visualize the fitted model gm by using pdf and fcontour.
scatter(X(:,1),X(:,2),10,'.') % Scatter plot with points of size 10 hold on gmPDF = @(x,y) arrayfun(@(x0,y0) pdf(gm,[x0 y0]),x,y); fcontour(gmPDF,[-8 6])
References
[1] McLachlan, G., and D. Peel. Finite Mixture Models. Hoboken, NJ: John Wiley & Sons, Inc., 2000.
Version History
Introduced in R2007b