loss
Loss for regression neural network
Description
L = loss(Mdl,Tbl,ResponseVarName)Mdl using the predictor data in table Tbl and
the response values in the ResponseVarName table variable. By
default, the regression loss is the mean squared error (MSE).
L = loss(___,Name=Value)
Examples
Calculate the test set mean squared error (MSE) of a regression neural network model.
Load the patients data set. Create a table from the data set. Each row corresponds to one patient, and each column corresponds to a diagnostic variable. Use the Systolic variable as the response variable, and the rest of the variables as predictors.
load patients
tbl = table(Diastolic,Height,Smoker,Weight,Systolic);Separate the data into a training set tblTrain and a test set tblTest by using a nonstratified holdout partition. The software reserves approximately 30% of the observations for the test data set and uses the rest of the observations for the training data set.
rng("default") % For reproducibility of the partition c = cvpartition(size(tbl,1),"Holdout",0.30); trainingIndices = training(c); testIndices = test(c); tblTrain = tbl(trainingIndices,:); tblTest = tbl(testIndices,:);
Train a regression neural network model using the training set. Specify the Systolic column of tblTrain as the response variable. Specify to standardize the numeric predictors, and set the iteration limit to 50.
Mdl = fitrnet(tblTrain,"Systolic", ... "Standardize",true,"IterationLimit",50);
Calculate the test set MSE. Smaller MSE values indicate better performance.
testMSE = loss(Mdl,tblTest,"Systolic")testMSE = 22.2447
Perform feature selection by comparing test set losses and predictions. Compare the test set metrics for a regression neural network model trained using all the predictors to the test set metrics for a model trained using only a subset of the predictors.
Load the sample file fisheriris.csv, which contains iris data including sepal length, sepal width, petal length, petal width, and species type. Read the file into a table.
fishertable = readtable('fisheriris.csv');Separate the data into a training set trainTbl and a test set testTbl by using a nonstratified holdout partition. The software reserves approximately 30% of the observations for the test data set and uses the rest of the observations for the training data set.
rng("default") c = cvpartition(size(fishertable,1),"Holdout",0.3); trainTbl = fishertable(training(c),:); testTbl = fishertable(test(c),:);
Train one regression neural network model using all the predictors in the training set, and train another model using all the predictors except PetalWidth. For both models, specify PetalLength as the response variable, and standardize the predictors.
allMdl = fitrnet(trainTbl,"PetalLength","Standardize",true); subsetMdl = fitrnet(trainTbl,"PetalLength ~ SepalLength + SepalWidth + Species", ... "Standardize",true);
Compare the test set mean squared error (MSE) of the two models. Smaller MSE values indicate better performance.
allMSE = loss(allMdl,testTbl)
allMSE = 0.0833
subsetMSE = loss(subsetMdl,testTbl)
subsetMSE = 0.0875
For each model, compare the test set predicted petal lengths to the true petal lengths. Plot the predicted petal lengths along the vertical axis and the true petal lengths along the horizontal axis. Points on the reference line indicate correct predictions.
tiledlayout(2,1) % Top axes ax1 = nexttile; allPredictedY = predict(allMdl,testTbl); plot(ax1,testTbl.PetalLength,allPredictedY,".") hold on plot(ax1,testTbl.PetalLength,testTbl.PetalLength) hold off xlabel(ax1,"True Petal Length") ylabel(ax1,"Predicted Petal Length") title(ax1,"All Predictors") % Bottom axes ax2 = nexttile; subsetPredictedY = predict(subsetMdl,testTbl); plot(ax2,testTbl.PetalLength,subsetPredictedY,".") hold on plot(ax2,testTbl.PetalLength,testTbl.PetalLength) hold off xlabel(ax2,"True Petal Length") ylabel(ax2,"Predicted Petal Length") title(ax2,"Subset of Predictors")
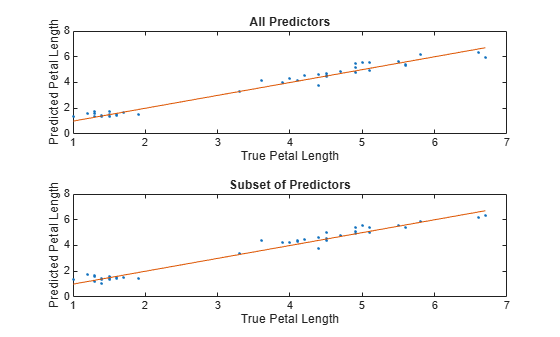
Because both models seems to perform well, with predictions scattered near the reference line, consider using the model trained using all predictors except PetalWidth.
Since R2024b
Create a regression neural network with more than one response variable.
Load the carbig data set, which contains measurements of cars made in the 1970s and early 1980s. Create a table containing the predictor variables Displacement, Horsepower, and so on, as well as the response variables Acceleration and MPG. Display the first eight rows of the table.
load carbig cars = table(Displacement,Horsepower,Model_Year, ... Origin,Weight,Acceleration,MPG); head(cars)
Displacement Horsepower Model_Year Origin Weight Acceleration MPG
____________ __________ __________ _______ ______ ____________ ___
307 130 70 USA 3504 12 18
350 165 70 USA 3693 11.5 15
318 150 70 USA 3436 11 18
304 150 70 USA 3433 12 16
302 140 70 USA 3449 10.5 17
429 198 70 USA 4341 10 15
454 220 70 USA 4354 9 14
440 215 70 USA 4312 8.5 14
Remove rows of cars where the table has missing values.
cars = rmmissing(cars);
Categorize the cars based on whether they were made in the USA.
cars.Origin = categorical(cellstr(cars.Origin)); cars.Origin = mergecats(cars.Origin,["France","Japan",... "Germany","Sweden","Italy","England"],"NotUSA");
Partition the data into training and test sets. Use approximately 85% of the observations to train a neural network model, and 15% of the observations to test the performance of the trained model on new data. Use cvpartition to partition the data.
rng("default") % For reproducibility c = cvpartition(height(cars),"Holdout",0.15); carsTrain = cars(training(c),:); carsTest = cars(test(c),:);
Train a multiresponse neural network regression model by passing the carsTrain training data to the fitrnet function. For better results, specify to standardize the predictor data.
Mdl = fitrnet(carsTrain,["Acceleration","MPG"], ... Standardize=true)
Mdl =
RegressionNeuralNetwork
PredictorNames: {'Displacement' 'Horsepower' 'Model_Year' 'Origin' 'Weight'}
ResponseName: {'Acceleration' 'MPG'}
CategoricalPredictors: 4
ResponseTransform: 'none'
NumObservations: 334
LayerSizes: 10
Activations: 'relu'
OutputLayerActivation: 'none'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [1000×7 table]
Properties, Methods
Mdl is a trained RegressionNeuralNetwork model. You can use dot notation to access the properties of Mdl. For example, you can specify Mdl.ConvergenceInfo to get more information about the model convergence.
Evaluate the performance of the regression model on the test set by computing the test mean squared error (MSE). Smaller MSE values indicate better performance. Return the loss for each response variable separately by setting the OutputType name-value argument to "per-response".
testMSE = loss(Mdl,carsTest,["Acceleration","MPG"], ... OutputType="per-response")
testMSE = 1×2
1.5341 4.8245
Predict the response values for the observations in the test set. Return the predicted response values as a table.
predictedY = predict(Mdl,carsTest,OutputType="table")predictedY=58×2 table
Acceleration MPG
____________ ______
9.3612 13.567
15.655 21.406
17.921 17.851
11.139 13.433
12.696 10.32
16.498 17.977
16.227 22.016
12.165 12.926
12.691 12.072
12.424 14.481
16.974 22.152
15.504 24.955
11.068 13.874
11.978 12.664
14.926 10.134
15.638 24.839
⋮