detectdrift
Detect drifts between baseline and target data using permutation testing
Since R2022a
Syntax
Description
DDiagnostics = detectdrift(Baseline,Target)Baseline and Target data sets, and
returns the results in DDiagnostics.
DDiagnostics is a DriftDiagnostics object.
DDiagnostics = detectdrift(Baseline,Target,Name=Value)
Examples
Generate baseline and target data with two variables, where the distribution parameters of the second variable change for the target data.
rng('default') % For reproducibility baseline = [normrnd(0,1,100,1),wblrnd(1.1,1,100,1)]; target = [normrnd(0,1,100,1),wblrnd(1.2,2,100,1)];
Compare the two data sets for any drift.
DDiagnostics = detectdrift(baseline,target)
DDiagnostics =
DriftDiagnostics
VariableNames: ["x1" "x2"]
CategoricalVariables: []
DriftStatus: ["Stable" "Drift"]
PValues: [0.2850 0.0030]
ConfidenceIntervals: [2×2 double]
MultipleTestDriftStatus: "Drift"
DriftThreshold: 0.0500
WarningThreshold: 0.1000
Properties, Methods
DDiagnostics is a DriftDiagnostics object. detectdrift displays some of the object properties.
Display the confidence intervals for the estimated p-values.
DDiagnostics.ConfidenceIntervals
ans = 2×2
0.2572 0.0006
0.3141 0.0087
For the first variable, the lower bound of the confidence interval for the estimated p-value is greater than the warning threshold value of 0.1. Therefore, detectdrift determines that the target data for the first variable is stable compared to the baseline data. For the second variable, the upper bound of the confidence interval for the estimated p-value is smaller than the drift threshold of 0.05. Therefore, the drift status for this variable is Drift, which indicates that detectdrift detects the shift in the distribution parameters.
detectdrift uses the default Bonferroni method for testing multiple hypotheses. The function first divides the warning and drift thresholds by the number of p-values, which in this case is two. Then the function determines if any p-value is still lower than either threshold. Here, the second p-value is still lower than the modified drift threshold, so the function sets the MultipleTestDriftStatus to Drift for the overall data.
Visualize the permutation results for both variables.
tiledlayout(2,1); ax1 = nexttile; plotPermutationResults(DDiagnostics,ax1,Variable="x1") ax2 = nexttile; plotPermutationResults(DDiagnostics,ax2,Variable="x2")
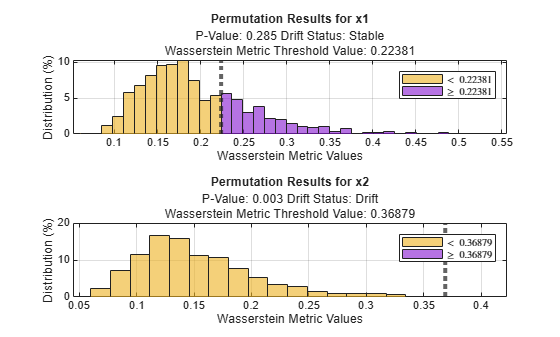
Bars to the right of the dashed line show the metric values that are greater than the threshold, which is the initial metric value detectdrift computes using the baseline and target data for each variable. The amount of the bars greater than the threshold is much more for variable x1, which indicates that there is not a significant drift between the baseline and target data for this variable.
Load the sample data.
load humanactivityFor details on the data set, enter Description at the command line.
Assign the first 250 observations as baseline data and next 250 as target data.
baseline = feat(1:250,:); target = feat(251:500,:);
Test for drift on variables 5 to 10 using a warning threshold of 0.05 and a drift threshold of 0.01. All variables are continuous, so use the Kolmogorov-Smirnov metric for all variables. Specify the False Discovery Rate method as the multiple test correction.
DDiagnostics = detectdrift(baseline(:,5:10),target(:,5:10),WarningThreshold=0.05, ... DriftThreshold=0.01,ContinuousMetric="ks",MultipleTestCorrection="fdr")
DDiagnostics =
DriftDiagnostics
VariableNames: ["x1" "x2" "x3" "x4" "x5" "x6"]
CategoricalVariables: []
DriftStatus: ["Drift" "Drift" "Drift" "Stable" "Warning" "Drift"]
PValues: [1.0000e-03 1.0000e-03 1.0000e-03 0.8810 0.0110 1.0000e-03]
ConfidenceIntervals: [2×6 double]
MultipleTestDriftStatus: "Drift"
DriftThreshold: 0.0100
WarningThreshold: 0.0500
Properties, Methods
Display the confidence intervals for the estimated p-values.
DDiagnostics.ConfidenceIntervals
ans = 2×6
0.0000 0.0000 0.0000 0.8593 0.0055 0.0000
0.0056 0.0056 0.0056 0.9004 0.0196 0.0056
The lower confidence bound of the p-value for the 8th variable (variable name x4) is greater than the warning threshold. Therefore, detectdrift determines that the drift status for this variable is "Stable". The upper confidence bound of the p-value for the 9th variable (variable name x5) is greater than the drift threshold, but lower than the warning threshold. Therefore, detectdrift determines that the drift status for this variable is "Warning". Confidence intervals of all other variables are smaller than the drift threshold, so they have a drift status of "Drift". Based on the False Discovery Rate method for multiple test correction, the function determines that the drift status for the overall data is "Drift".
Visualize the p-values with the confidence intervals and corresponding drift status.
plotDriftStatus(DDiagnostics)
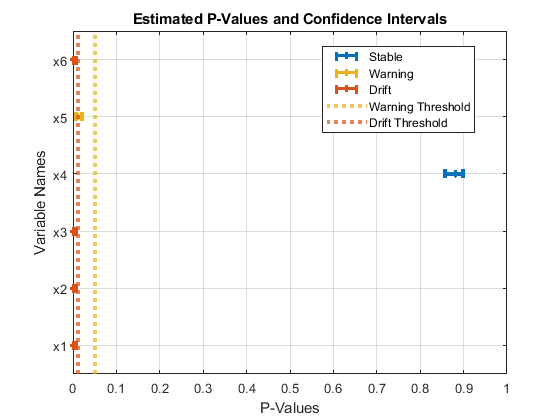
The plot shows the estimated p-values with the confidence intervals against the warning and drift thresholds. The estimated p-value for variable x4 and its confidence intervals are higher than the warning threshold. Therefore, the drift status for this variable is "Stable". The upper confidence bound of the p-value for x5 is greater than the drift threshold, but lower than the warning threshold. Therefore, the drift status for this variable is "Warning". Confidence intervals of all other variables are smaller than the drift threshold, so they have a drift status of "Drift".
Load the data set NYCHousing2015.
load NYCHousing2015The data set includes 10 variables with information on the sales of properties in New York City in 2015.
Remove outliers and convert the datetime array (SALEDATE) to the month numbers.
idx = isoutlier(NYCHousing2015.SALEPRICE); NYCHousing2015(idx,:) = []; NYCHousing2015.SALEDATE = month(NYCHousing2015.SALEDATE);
Define the baseline and target data as information on the sales made in January and July, respectively.
tbl = NYCHousing2015; baseline = tbl(tbl.SALEDATE==1,:); target = tbl(tbl.SALEDATE==7,:);
Shuffle the data.
n = numel(baseline(:,1));
rng(1); % For reproducibility
idx = randsample(n,n);
baseline = baseline(idx,:);
n = numel(target(:,1));
idx = randsample(n,n);
target = target(idx,:);Test for potential drift between the baseline and target data. Specify the categorical variables and the metrics to use with each variable.
DDiagnostics = detectdrift(baseline(1:1500,:),target(1:1500,:), ... VariableNames=["BOROUGH","BUILDINGCLASSCATEGORY","LANDSQUAREFEET","GROSSSQUAREFEET","SALEPRICE"], ... CategoricalVariables=["BOROUGH","BUILDINGCLASSCATEGORY"], ... Metrics=["Hellinger","Hellinger","ad","ks","energy"])
DDiagnostics =
DriftDiagnostics
VariableNames: ["BOROUGH" "BUILDINGCLASSCATEGORY" "LANDSQUAREFEET" "GROSSSQUAREFEET" "SALEPRICE"]
CategoricalVariables: [1 2]
DriftStatus: ["Drift" "Stable" "Drift" "Drift" "Drift"]
PValues: [0.0260 0.1440 0.0070 0.0230 0.0110]
ConfidenceIntervals: [2×5 double]
MultipleTestDriftStatus: "Drift"
DriftThreshold: 0.0500
WarningThreshold: 0.1000
Properties, Methods
detectdrift identifies drift between the baseline and target data for all variables except BUILDINGCLASSCATEGORY.
Display the confidence intervals for the estimated p-values.
DDiagnostics.ConfidenceIntervals
ans = 2×5
0.0171 0.1228 0.0028 0.0146 0.0055
0.0379 0.1673 0.0144 0.0343 0.0196
Plot a histogram for SALEPRICE.
plotHistogram(DDiagnostics,Variable="SALEPRICE")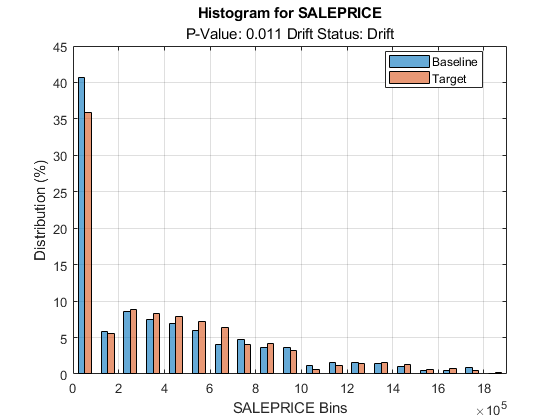
The histogram shows the shift in the sale prices for the month of July compared to January.
Plot the empirical cumulative distribution function for the baseline and target data of SALEPRICE.
plotEmpiricalCDF(DDiagnostics,Variable="SALEPRICE")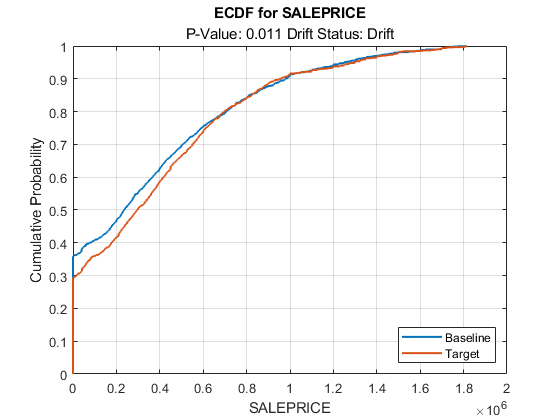
Plot the permutation results for SALEPRICE.
plotPermutationResults(DDiagnostics,Variable="SALEPRICE")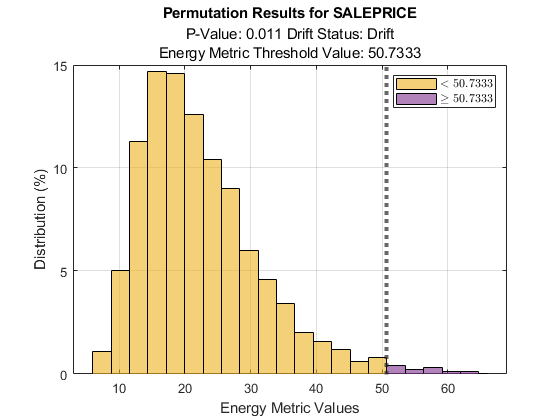
Generate baseline and target data with three variables, where the distribution parameters of the second and third variables change for the target data.
rng('default') % For reproducibility baseline = [normrnd(0,1,100,1),wblrnd(1.1,1,100,1),betarnd(1,2,100,1)]; target = [normrnd(0,1,100,1),wblrnd(1.2,2,100,1),betarnd(1.7,2.8,100,1)];
Compute the initial metrics for all variables between the baseline and target data without estimating the p-values.
DDiagnostics = detectdrift(baseline,target,EstimatePValues=false)
DDiagnostics =
DriftDiagnostics
VariableNames: ["x1" "x2" "x3"]
CategoricalVariables: []
Metrics: ["Wasserstein" "Wasserstein" "Wasserstein"]
MetricValues: [0.2022 0.3468 0.0559]
Properties, Methods
detectdrift computes only the initial metric value for each variable using the baseline and target data. The properties associated with permutation testing and p-value estimation are either empty or contain NaNs.
summary(DDiagnostics)
MetricValue Metric
___________ _____________
x1 0.20215 "Wasserstein"
x2 0.34676 "Wasserstein"
x3 0.055922 "Wasserstein"
summary function displays only the initial metric value and the metric used for each specified variable.
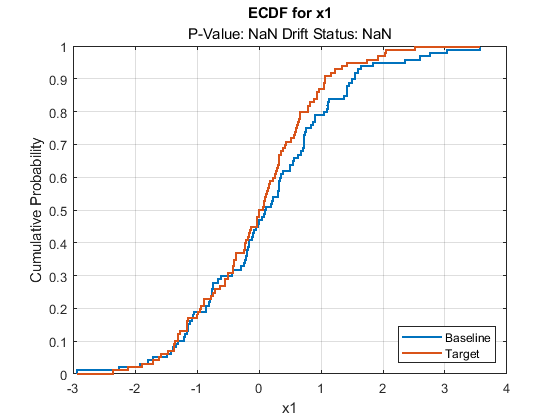
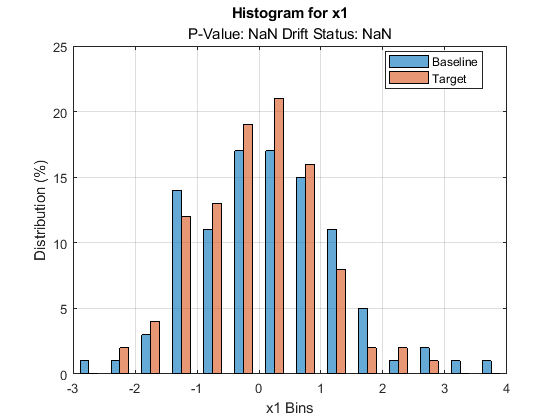
plotDriftStatus and plotPermutationResults do not produce plots and return warning messages when you compute metrics without estimating p-values. plotEmpiricalCDF and plotHistogram plot the ecdf and the histogram, respectively, for the first variable by default. They both return NaN for the p-value and drift status associated with the variable.
plotEmpiricalCDF(DDiagnostics)
plotHistogram(DDiagnostics)
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
References
[1] Hesterbeg,Tim, David S. Moore, Shaun Monaghan, Ashley Clipson, and Rachel Epstein. "Bootstrap Methods and Permutation Tests" in Introduction to the Practice of Statistics. 7th ed, W.H. Freeman, pp. 1–57, 2010.
[2] Benjamini, Yoav, and Yosef Hochberg. "Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing." Journal of the Royal Statistical Society, Series B (Methodological). Vol. 57, No. 1, pp. 289-300, 1995.
[3] Villani, Cédric. Topics in Optimal Transportation. Graduate Studies in Mathematics. Vol. 58, American Mathematical Society, 2000.
[4] Deza, Elena, and Michel Marie Deza. Encyclopedia of Distances, Springer Berlin Heidelberg, 2009.
Extended Capabilities
Version History
Introduced in R2022aSee Also
DriftDiagnostics | ecdf | histcounts | plotDriftStatus | plotEmpiricalCDF | plotHistogram | plotPermutationResults | summary