CompactTreeBagger
Compact ensemble of bagged decision trees
Description
CompactTreeBagger is a compact version of the TreeBagger ensemble. The compact ensemble does not contain the following:
information about how the TreeBagger function grows the decision
trees; the input data used for growing trees; or the training parameters (for example,
minimal leaf size, number of variables sampled for each decision split at random, and so
on). Use CompactTreeBagger for tasks such as predicting the response or
class labels.
Creation
Create a CompactTreeBagger ensemble object from a full, trained
TreeBagger ensemble by using compact.
Properties
Object Functions
combine | Combine two ensembles |
error | Error (misclassification probability or MSE) |
margin | Classification margin |
mdsprox | Multidimensional scaling of proximity matrix |
meanMargin | Mean classification margin |
outlierMeasure | Outlier measure for data in ensemble of decision trees |
partialDependence | Compute partial dependence |
plotPartialDependence | Create partial dependence plot (PDP) and individual conditional expectation (ICE) plots |
predict | Predict responses using ensemble of bagged decision trees |
proximity | Proximity matrix for data in ensemble of decision trees |
setDefaultYfit | Set default value for predict |
Examples
Reduce the size of a full ensemble of bagged classification trees by removing the training data and parameters. Then, use the compact ensemble object to make predictions on new data. Using a compact ensemble improves memory efficiency.
Load the ionosphere data set.
load ionosphereSet the random number generator to default for reproducibility.
rng("default")Train an ensemble of 100 bagged classification trees using the entire data set. By default, TreeBagger grows deep trees.
Mdl = TreeBagger(100,X,Y,... Method="classification");
Mdl is a TreeBagger ensemble for classification trees.
Create a compact version of Mdl.
CMdl = compact(Mdl)
CMdl =
CompactTreeBagger
Ensemble with 100 bagged decision trees:
Method: classification
NumPredictors: 34
ClassNames: 'b' 'g'
Properties, Methods
CMdl is a CompactTreeBagger ensemble for classification trees.
Display the amount of memory used by each ensemble.
whos("Mdl","CMdl")
Name Size Bytes Class Attributes CMdl 1x1 946024 CompactTreeBagger Mdl 1x1 1087351 TreeBagger
Mdl takes up more space than CMdl.
The CMdl.Trees property is a 100-by-1 cell vector that contains the trained classification trees for the ensemble. Each tree is a CompactClassificationTree object. View the graphical display of the first trained classification tree.
view(CMdl.Trees{1},Mode="graph");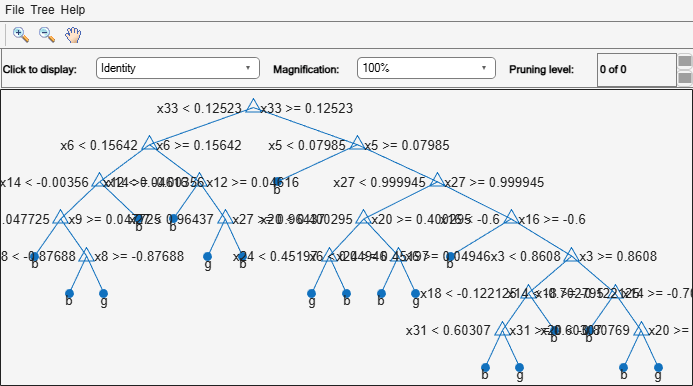
Predict the label of the mean of X by using the compact ensemble.
predMeanX = predict(CMdl,mean(X))
predMeanX = 1×1 cell array
{'g'}
Tips
For a
CompactTreeBaggermodelCMdl, theTreesproperty contains a cell vector ofCMdl.NumTreesCompactClassificationTreeorCompactRegressionTreeobjects. View the graphical display of thetgrown tree by entering:view(CMdl.Trees{t})
Version History
Introduced in R2009a