predict
Predict top LDA topics of documents
Syntax
Description
___ = predict(___,
specifies additional options using one or more name-value pair arguments.Name,Value)
Examples
To reproduce the results in this example, set rng to 'default'.
rng('default')Load the example data. The file sonnetsPreprocessed.txt contains preprocessed versions of Shakespeare's sonnets. The file contains one sonnet per line, with words separated by a space. Extract the text from sonnetsPreprocessed.txt, split the text into documents at newline characters, and then tokenize the documents.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);Create a bag-of-words model using bagOfWords.
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
Counts: [154×3092 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" "contracted" … ]
NumWords: 3092
NumDocuments: 154
Fit an LDA model with 20 topics.
numTopics = 20; mdl = fitlda(bag,numTopics)
Initial topic assignments sampled in 0.513255 seconds. ===================================================================================== | Iteration | Time per | Relative | Training | Topic | Topic | | | iteration | change in | perplexity | concentration | concentration | | | (seconds) | log(L) | | | iterations | ===================================================================================== | 0 | 0.04 | | 1.159e+03 | 5.000 | 0 | | 1 | 0.05 | 5.4884e-02 | 8.028e+02 | 5.000 | 0 | | 2 | 0.04 | 4.7400e-03 | 7.778e+02 | 5.000 | 0 | | 3 | 0.04 | 3.4597e-03 | 7.602e+02 | 5.000 | 0 | | 4 | 0.03 | 3.4662e-03 | 7.430e+02 | 5.000 | 0 | | 5 | 0.03 | 2.9259e-03 | 7.288e+02 | 5.000 | 0 | | 6 | 0.03 | 6.4180e-05 | 7.291e+02 | 5.000 | 0 | =====================================================================================
mdl =
ldaModel with properties:
NumTopics: 20
WordConcentration: 1
TopicConcentration: 5
CorpusTopicProbabilities: [0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500]
DocumentTopicProbabilities: [154×20 double]
TopicWordProbabilities: [3092×20 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" … ]
TopicOrder: 'initial-fit-probability'
FitInfo: [1×1 struct]
Predict the top topics for an array of new documents.
newDocuments = tokenizedDocument([
"what's in a name? a rose by any other name would smell as sweet."
"if music be the food of love, play on."]);
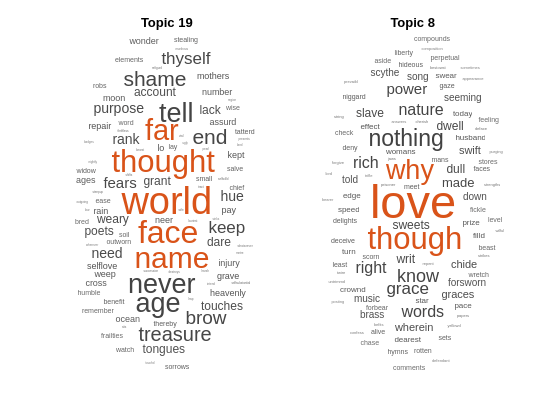
topicIdx = predict(mdl,newDocuments)topicIdx = 2×1
19
8
Visualize the predicted topics using word clouds.
figure subplot(1,2,1) wordcloud(mdl,topicIdx(1)); title("Topic " + topicIdx(1)) subplot(1,2,2) wordcloud(mdl,topicIdx(2)); title("Topic " + topicIdx(2))
Load the example data. sonnetsCounts.mat contains a matrix of word counts and a corresponding vocabulary of preprocessed versions of Shakespeare's sonnets.
load sonnetsCounts.mat
size(counts)ans = 1×2
154 3092
Fit an LDA model with 20 topics. To reproduce the results in this example, set rng to 'default'.
rng('default')
numTopics = 20;
mdl = fitlda(counts,numTopics)Initial topic assignments sampled in 0.023944 seconds. ===================================================================================== | Iteration | Time per | Relative | Training | Topic | Topic | | | iteration | change in | perplexity | concentration | concentration | | | (seconds) | log(L) | | | iterations | ===================================================================================== | 0 | 0.00 | | 1.159e+03 | 5.000 | 0 | | 1 | 0.02 | 5.4884e-02 | 8.028e+02 | 5.000 | 0 | | 2 | 0.01 | 4.7400e-03 | 7.778e+02 | 5.000 | 0 | | 3 | 0.01 | 3.4597e-03 | 7.602e+02 | 5.000 | 0 | | 4 | 0.01 | 3.4662e-03 | 7.430e+02 | 5.000 | 0 | | 5 | 0.02 | 2.9259e-03 | 7.288e+02 | 5.000 | 0 | | 6 | 0.01 | 6.4180e-05 | 7.291e+02 | 5.000 | 0 | =====================================================================================
mdl =
ldaModel with properties:
NumTopics: 20
WordConcentration: 1
TopicConcentration: 5
CorpusTopicProbabilities: [0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500]
DocumentTopicProbabilities: [154×20 double]
TopicWordProbabilities: [3092×20 double]
Vocabulary: ["1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11" "12" "13" "14" "15" "16" "17" "18" "19" "20" "21" "22" "23" "24" "25" "26" … ] (1×3092 string)
TopicOrder: 'initial-fit-probability'
FitInfo: [1×1 struct]
Predict the top topics for the first 5 documents in counts.
topicIdx = predict(mdl,counts(1:5,:))
topicIdx = 5×1
3
15
19
3
14
To reproduce the results in this example, set rng to 'default'.
rng('default')Load the example data. The file sonnetsPreprocessed.txt contains preprocessed versions of Shakespeare's sonnets. The file contains one sonnet per line, with words separated by a space. Extract the text from sonnetsPreprocessed.txt, split the text into documents at newline characters, and then tokenize the documents.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);Create a bag-of-words model using bagOfWords.
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
NumWords: 3092
Counts: [154×3092 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" … ] (1×3092 string)
NumDocuments: 154
Fit an LDA model with 20 topics. To suppress verbose output, set 'Verbose' to 0.
numTopics = 20;
mdl = fitlda(bag,numTopics,'Verbose',0);Predict the top topics for a new document. Specify the iteration limit to be 200.
newDocument = tokenizedDocument("what's in a name? a rose by any other name would smell as sweet."); iterationLimit = 200; [topicIdx,scores] = predict(mdl,newDocument, ... 'IterationLimit',iterationLimit)
topicIdx = 19
scores = 1×20
0.0250 0.0250 0.0250 0.0250 0.1250 0.0250 0.0250 0.0250 0.0250 0.0730 0.0250 0.0250 0.0770 0.0250 0.0250 0.0250 0.0250 0.0250 0.2250 0.1250
View the prediction scores in a bar chart.
figure bar(scores) title("LDA Topic Prediction Scores") xlabel("Topic Index") ylabel("Score")

Input Arguments
Name-Value Arguments
Output Arguments
Version History
Introduced in R2017b