dbscan
Density-based spatial clustering of applications with noise (DBSCAN)
Syntax
Description
idx = dbscan(X,epsilon,minpts)X into clusters using the DBSCAN algorithm (see Algorithms).
dbscan clusters the observations (or points) based on a threshold
for a neighborhood search radius epsilon and a minimum number of
neighbors minpts required to identify a core point. The function
returns an n-by-1 vector (idx) containing cluster
indices of each observation.
idx = dbscan(D,epsilon,minpts,'Distance','precomputed')D between observations. D can be the output of
pdist or pdist2, or a more general dissimilarity vector or matrix conforming to the
output format of pdist or pdist2,
respectively.
Examples
Cluster a 2-D circular data set using DBSCAN with the default Euclidean distance metric. Also, compare the results of clustering the data set using DBSCAN and k-Means clustering with the squared Euclidean distance metric.
Generate synthetic data that contains two noisy circles.
rng('default') % For reproducibility % Parameters for data generation N = 300; % Size of each cluster r1 = 0.5; % Radius of first circle r2 = 5; % Radius of second circle theta = linspace(0,2*pi,N)'; X1 = r1*[cos(theta),sin(theta)]+ rand(N,1); X2 = r2*[cos(theta),sin(theta)]+ rand(N,1); X = [X1;X2]; % Noisy 2-D circular data set
Visualize the data set.
scatter(X(:,1),X(:,2))
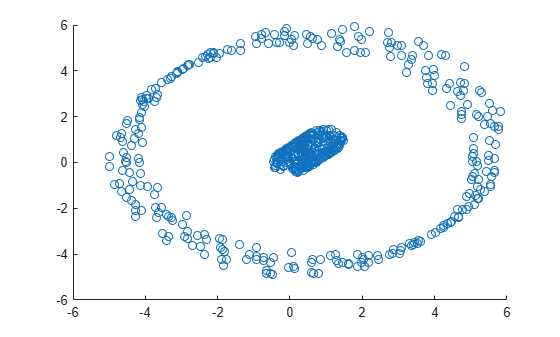
The plot shows that the data set contains two distinct clusters.
Perform DBSCAN clustering on the data. Specify an epsilon value of 1 and a minpts value of 5.
idx = dbscan(X,1,5); % The default distance metric is Euclidean distanceVisualize the clustering.
gscatter(X(:,1),X(:,2),idx);
title('DBSCAN Using Euclidean Distance Metric')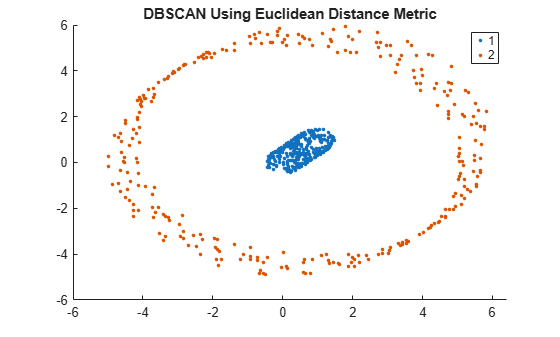
Using the Euclidean distance metric, DBSCAN correctly identifies the two clusters in the data set.
Perform DBSCAN clustering using the squared Euclidean distance metric. Specify an epsilon value of 1 and a minpts value of 5.
idx2 = dbscan(X,1,5,'Distance','squaredeuclidean');
Visualize the clustering.
gscatter(X(:,1),X(:,2),idx2);
title('DBSCAN Using Squared Euclidean Distance Metric')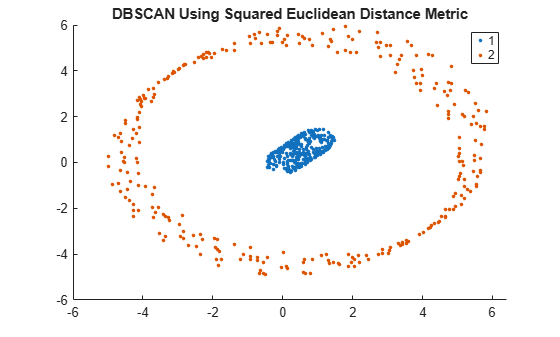
Using the squared Euclidean distance metric, DBSCAN correctly identifies the two clusters in the data set.
Perform k-Means clustering using the squared Euclidean distance metric. Specify k = 2 clusters.
kidx = kmeans(X,2); % The default distance metric is squared Euclidean distanceVisualize the clustering.
gscatter(X(:,1),X(:,2),kidx);
title('K-Means Using Squared Euclidean Distance Metric')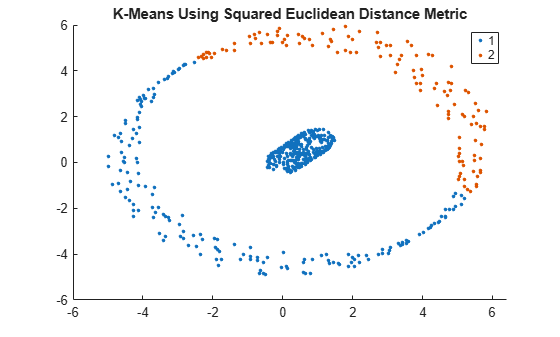
Using the squared Euclidean distance metric, k-Means clustering fails to correctly identify the two clusters in the data set.
Perform DBSCAN clustering using a matrix of pairwise distances between observations as input to the dbscan function, and find the number of outliers and core points. The data set is a Lidar scan, stored as a collection of 3-D points, that contains the coordinates of objects surrounding a vehicle.
Load the x, y, z coordinates of the objects.
load('lidar_subset.mat')
loc = lidar_subset;To highlight the environment around the vehicle, set the region of interest to span 20 meters to the left and right of the vehicle, 20 meters in front and back of the vehicle, and the area above the surface of the road.
xBound = 20; % in meters yBound = 20; % in meters zLowerBound = 0; % in meters
Crop the data to contain only points within the specified region.
indices = loc(:,1) <= xBound & loc(:,1) >= -xBound ... & loc(:,2) <= yBound & loc(:,2) >= -yBound ... & loc(:,3) > zLowerBound; loc = loc(indices,:);
Visualize the data as a 2-D scatter plot. Annotate the plot to highlight the vehicle.
scatter(loc(:,1),loc(:,2),'.'); annotation('ellipse',[0.48 0.48 .1 .1],'Color','red')
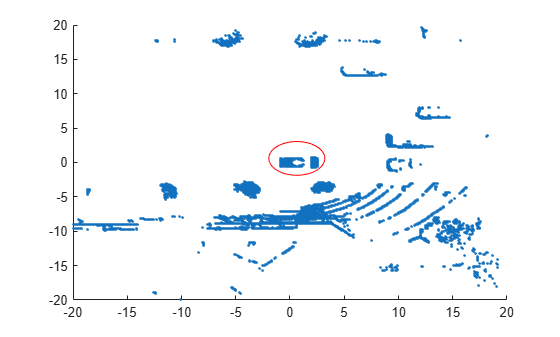
The center of the set of points (circled in red) contains the roof and hood of the vehicle. All other points are obstacles.
Precompute a matrix of pairwise distances D between observations by using the pdist2 function.
D = pdist2(loc,loc);
Cluster the data by using dbscan with the pairwise distances. Specify an epsilon value of 2 and a minpts value of 50.
[idx, corepts] = dbscan(D,2,50,'Distance','precomputed');
Visualize the results and annotate the figure to highlight a specific cluster.
numGroups = length(unique(idx)); gscatter(loc(:,1),loc(:,2),idx,hsv(numGroups)); annotation('ellipse',[0.54 0.41 .07 .07],'Color','red') grid
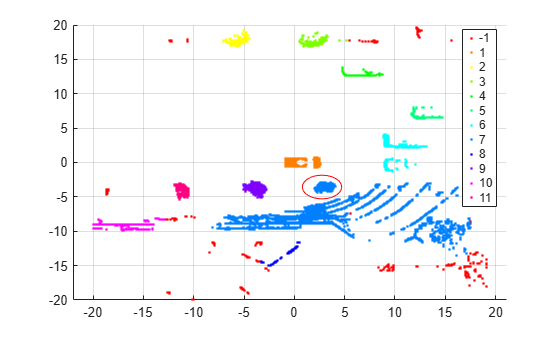
As shown in the scatter plot, dbscan identifies 11 clusters and places the vehicle in a separate cluster.
dbscan assigns the group of points circled in red (and centered around (3,–4)) to the same cluster (group 7) as the group of points in the southeast quadrant of the plot. The expectation is that these groups should be in separate clusters. You can try using a smaller value of epsilon to split up large clusters and further partition the points.
The function also identifies some outliers (an idx value of –1 ) in the data. Find the number of points that dbscan identifies as outliers.
sum(idx == -1)
ans = 412
dbscan identifies 412 outliers out of 19,070 observations.
Find the number of points that dbscan identifies as core points. A corepts value of 1 indicates a core point.
sum(corepts == 1)
ans = 18446
dbscan identifies 18,446 observations as core points.
See Determine Values for DBSCAN Parameters for a more extensive example.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
For improved speed when iterating over many values of
epsilon, consider passing inDas the input todbscan. This approach prevents the function from having to compute the distances at every point of the iteration.If you use
pdist2to precomputeD, do not specify the'Smallest'or'Largest'name-value pair arguments ofpdist2to select or sort columns ofD. Selecting fewer than n distances results in an error, becausedbscanexpectsDto be a square matrix. Sorting the distances in each column ofDleads to a loss in the interpretation ofDand can give meaningless results when used in thedbscanfunction.For efficient memory usage, consider passing in
Das a logical matrix rather than a numeric matrix todbscanwhenDis large. By default, MATLAB® stores each value in a numeric matrix using 8 bytes (64 bits), and each value in a logical matrix using 1 byte (8 bits).To select a value for
minpts, consider a value greater than or equal to the number of dimensions of the input data plus one [1]. For example, for an n-by-p matrixX, set'minpts'equal to p+1 or greater.One possible strategy for selecting a value for
epsilonis to generate a k-distance graph forX. For each point inX, find the distance to the kth nearest point, and plot sorted points against this distance. Generally, the graph contains a knee. The distance that corresponds to the knee is typically a good choice forepsilon, because it is the region where points start tailing off into outlier (noise) territory [1].
Algorithms
DBSCAN is a density-based clustering algorithm that is designed to discover clusters and noise in data. The algorithm identifies three kinds of points: core points, border points, and noise points [1]. For specified values of
epsilonandminpts, thedbscanfunction implements the algorithm as follows:From the input data set
X, select the first unlabeled observation x1 as the current point, and initialize the first cluster label C to 1.Find the set of points within the epsilon neighborhood
epsilonof the current point. These points are the neighbors.If the number of neighbors is less than
minpts, then label the current point as a noise point (or an outlier). Go to step 4.Note
dbscancan reassign noise points to clusters if the noise points later satisfy the constraints set byepsilonandminptsfrom some other point inX. This process of reassigning points happens for border points of a cluster.Otherwise, label the current point as a core point belonging to cluster C.
Iterate over each neighbor (new current point) and repeat step 2 until no new neighbors are found that can be labeled as belonging to the current cluster C.
Select the next unlabeled point in
Xas the current point, and increase the cluster count by 1.Repeat steps 2–4 until all points in
Xare labeled.
If two clusters have varying densities and are close to each other, that is, the distance between two border points (one from each cluster) is less than
epsilon, thendbscancan merge the two clusters into one.Every valid cluster might not contain at least
minptsobservations. For example,dbscancan identify a border point belonging to two clusters that are close to each other. In such a situation, the algorithm assigns the border point to the first discovered cluster. As a result, the second cluster is still a valid cluster, but it can have fewer thanminptsobservations.
References
[1] Ester, M., H.-P. Kriegel, J. Sander, and X. Xiaowei. “A density-based algorithm for discovering clusters in large spatial databases with noise.” In Proceedings of the Second International Conference on Knowledge Discovery in Databases and Data Mining, 226-231. Portland, OR: AAAI Press, 1996.
Extended Capabilities
Version History
Introduced in R2019a