kfoldPredict
Classify observations in cross-validated kernel classification model
Description
label = kfoldPredict(CVMdl)ClassificationPartitionedKernel) CVMdl. For every fold,
kfoldPredict predicts class labels for validation-fold observations
using a model trained on training-fold observations.
[
also returns classification scores
for both classes.label,score] = kfoldPredict(CVMdl)
Examples
Classify observations using a cross-validated, binary kernel classifier, and display the confusion matrix for the resulting classification.
Load the ionosphere data set. This data set has 34 predictors and 351 binary responses for radar returns, which are labeled either bad ('b') or good ('g').
load ionosphereCross-validate a binary kernel classification model using the data.
rng(1); % For reproducibility CVMdl = fitckernel(X,Y,'Crossval','on')
CVMdl =
ClassificationPartitionedKernel
CrossValidatedModel: 'Kernel'
ResponseName: 'Y'
NumObservations: 351
KFold: 10
Partition: [1×1 cvpartition]
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
Properties, Methods
CVMdl is a ClassificationPartitionedKernel model. By default, the software implements 10-fold cross-validation. To specify a different number of folds, use the 'KFold' name-value pair argument instead of 'Crossval'.
Classify the observations that fitckernel does not use in training the folds.
label = kfoldPredict(CVMdl);
Construct a confusion matrix to compare the true classes of the observations to their predicted labels.
C = confusionchart(Y,label);
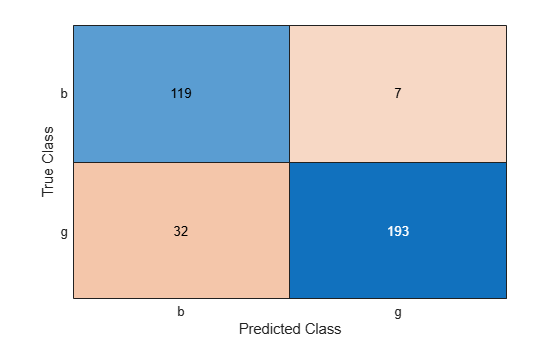
The CVMdl model misclassifies 32 good ('g') radar returns as being bad ('b') and misclassifies 7 bad radar returns as being good.
Estimate posterior class probabilities using a cross-validated, binary kernel classifier, and determine the quality of the model by plotting a receiver operating characteristic (ROC) curve. Cross-validated kernel classification models return posterior probabilities for logistic regression learners only.
Load the ionosphere data set. This data set has 34 predictors and 351 binary responses for radar returns, which are labeled either bad ('b') or good ('g').
load ionosphereCross-validate a binary kernel classification model using the data. Specify the class order, and fit logistic regression learners.
rng(1); % For reproducibility CVMdl = fitckernel(X,Y,'Crossval','on', ... 'ClassNames',{'b','g'},'Learner','logistic')
CVMdl =
ClassificationPartitionedKernel
CrossValidatedModel: 'Kernel'
ResponseName: 'Y'
NumObservations: 351
KFold: 10
Partition: [1×1 cvpartition]
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
Properties, Methods
CVMdl is a ClassificationPartitionedKernel model. By default, the software implements 10-fold cross-validation. To specify a different number of folds, use the 'KFold' name-value pair argument instead of 'Crossval'.
Predict the posterior class probabilities for the observations that fitckernel does not use in training the folds.
[~,posterior] = kfoldPredict(CVMdl);
The output posterior is a matrix with two columns and n rows, where n is the number of observations. Column i contains posterior probabilities of CVMdl.ClassNames(i) given a particular observation.
Compute the performance metrics (true positive rates and false positive rates) for a ROC curve and find the area under the ROC curve (AUC) value by creating a rocmetrics object.
rocObj = rocmetrics(Y,posterior,CVMdl.ClassNames);
Plot the ROC curve for the second class by using the plot function of rocmetrics.
plot(rocObj,ClassNames=CVMdl.ClassNames(2))
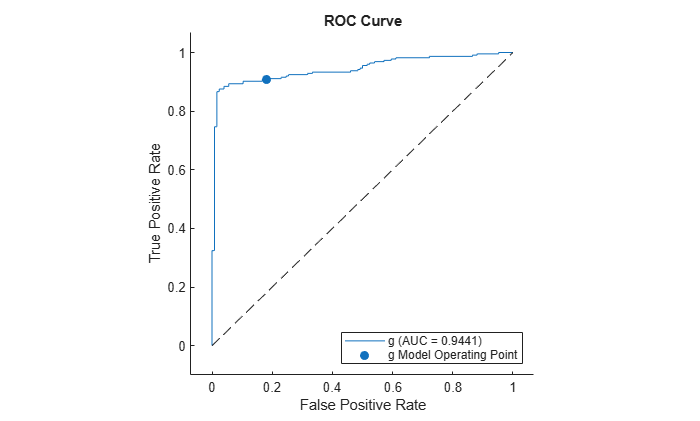
The AUC is close to 1, which indicates that the model predicts labels well.