Prevent Kernel Launches Inside Loops
This example shows how to prevent kernel launches inside a loop in generated CUDA® code by turning the loop into a kernel. Launching kernels inside of loops can slow down an application because the loop launches each kernel sequentially and each launch causes a significant amount of overhead on the CPU. Turning the loop into a kernel enables the application to launch fewer kernels with more threads.
Examine and Profile the kernelInLoop Function
The kernelInLoop function takes the input matrix in and loops over its columns and then its rows to create the output. It creates a variable t that is equal to 1 while looping over the first column and 0 otherwise.
type kernelInLoop.mfunction out = kernelInLoopSeparate(in)
coder.gpu.kernelfun;
out = coder.nullcopy(in);
for j = 1:size(in, 2)
t = 0;
if j == 1
t = addOne(t);
end
for i = 1:size(in, 1)
out(i, j) = addTwo(in(i, j)) + t;
end
end
end
function b = addOne(a)
b = a + 1;
end
function a = addTwo(a)
a = a + 2;
end
Create a coder.gpuConfig configuration object and a 300-by-100 input array in. Profile the function using the gpuPerformanceAnalyzer function.
cfg = coder.gpuConfig("mex"); in = gpuArray(rand(300,100)); gpuPerformanceAnalyzer("kernelInLoop.m",{in},Config=cfg);
### Starting GPU code generation Code generation successful: View report ### GPU code generation finished ### Starting application profiling ### Application profiling finished ### Starting profiling data processing ### Profiling data processing finished ### Showing profiling data
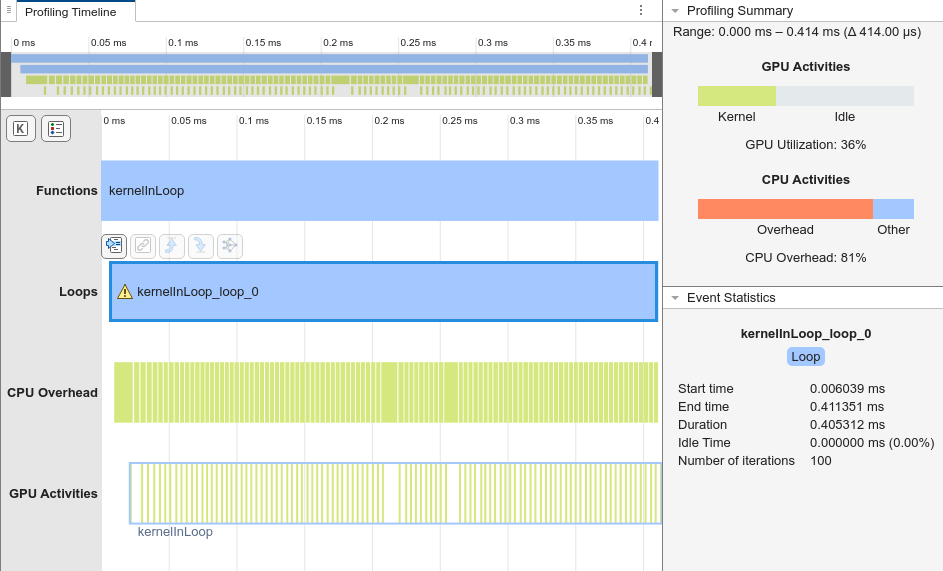
The Performance Analyzer results show the loop kernelInLoop_loop_0 takes 0.411 ms out of the 0.414 ms the generated code takes to execute. Additionally, the CPU overhead is 81%. These results are from profiling on a machine with an Intel® Xeon® CPU ES-1650 at 3.60Hx x12 and an NVIDIA® Quadro® RTX 6000 GPU.
In the generated code, the loop iterates over the 100 columns of the input, calculates the value of t, and then launches a kernel that uses t to compute the output.
Optimize the Nested Loop to Launch Fewer Kernels
To optimize the loop the causes repeated kernel launches in the generated code, you can parallelize the loop by moving calculations to the innermost level of the loop. Alternatively, you can split the loop into multiple loops that calculate the result for different values of t.
Parallelize Loop That Contains Kernel Launches
To avoid launching kernels inside a loop, restructure the code to transform the loop into a kernel. GPU Coder tries to flatten nested loops into one loop that it can generate as a kernel. In this example, the outermost loop in the kernelInLoop function calculates t before entering the inner loop, which prevents GPU coder from flattening the loop. To optimize the nested loop, restructure it so that it does not have any code between the loops.
Create a new function named kernelInLoopFused that calculates t inside the innermost loop.
type kernelInLoopFused.mfunction out = kernelInLoopFused(in)
coder.gpu.kernelfun;
out = coder.nullcopy(in);
for j = 1:size(in, 2)
for i = 1:size(in, 1)
t = 0;
if j == 1
t = addOne(t);
end
out(i, j) = addTwo(in(i, j)) + t;
end
end
end
function b = addOne(a)
b = a + 1;
end
function a = addTwo(a)
a = a + 2;
end
Profile the kernelInLoopFused function using the GPU Performance Analyzer.
gpuPerformanceAnalyzer("kernelInLoopFused.m",{in},Config=cfg);### Starting GPU code generation Code generation successful: View report ### GPU code generation finished ### Starting application profiling ### Application profiling finished ### Starting profiling data processing ### Profiling data processing finished ### Showing profiling data
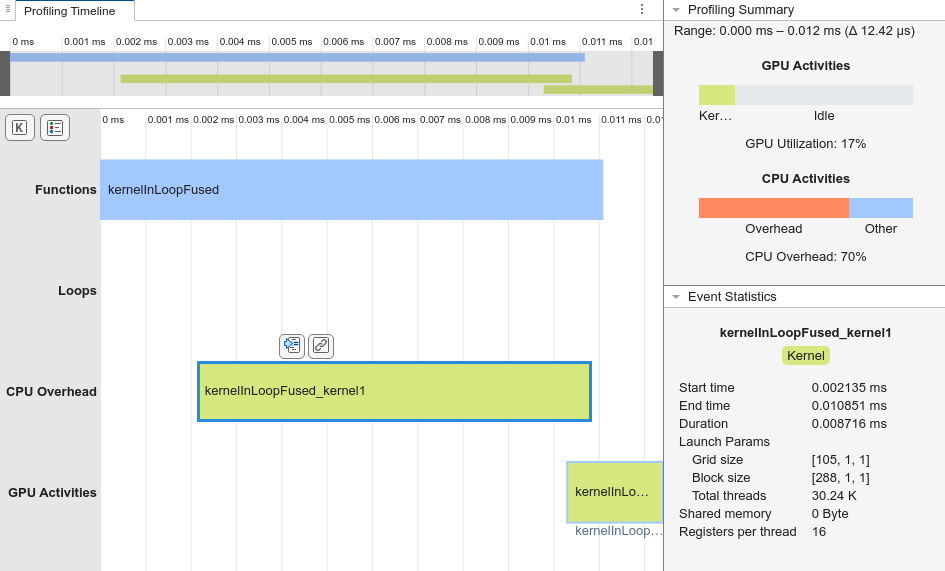
The generated code does not contain any loop events and generates one kernel, kernelInLoopFused_kernel1. The generated code takes only 0.012 ms to execute, which is more than 30 times faster than the generated code for the kernelInLoop function.
Split the Nested Loop Into Multiple Loops
Alternatively, you can optimize the nested loop by calculating t outside the loop and using multiple loops to calculate out. Because the value of t is 1 while looping over the first column of in and 0 otherwise, you can partition the loop into two loops that calculate the first column and the rest of the columns of out, respectively. Create a function named kernelInLoopSeparate that calculates out using two loops.
type kernelInLoopSeparate;function out = kernelInLoopSeparate(in)
coder.gpu.kernelfun;
out = coder.nullcopy(in);
% Calculate the result for everything but the first column.
t = 0;
for j = 2:size(in, 2)
for i = 1:size(in, 1)
out(i, j) = addTwo(in(i, j)) + t;
end
end
% Calculate the result for the first column.
t = addOne(t);
for i = 1:size(in, 1)
out(i, 1) = addTwo(in(i, 1)) + t;
end
end
function b = addOne(a)
b = a + 1;
end
function a = addTwo(a)
a = a + 2;
end
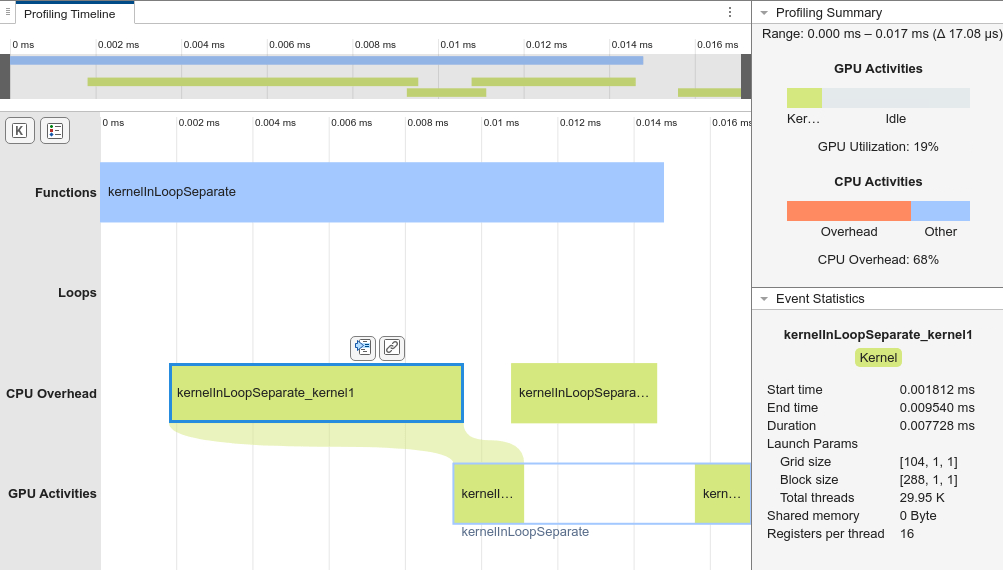
Profile the kernelInLoopSeparate function using the GPU Performance Analyzer. Because the calculation of t is outside the loop, the code generates the original for-loop as a kernel.
gpuPerformanceAnalyzer("kernelInLoopSeparate",{in},Config=cfg);### Starting GPU code generation Code generation successful: View report ### GPU code generation finished ### Starting application profiling ### Application profiling finished ### Starting profiling data processing ### Profiling data processing finished ### Showing profiling data