Real Divide HDL Optimized
Divide one real input by another using CORDIC algorithm and generate optimized HDL code

Libraries:
Fixed-Point Designer HDL Support /
Math Operations
Description
The Real Divide HDL Optimized block outputs the result of dividing the real scalar num by the real scalar den, such that y = num/den.
Examples
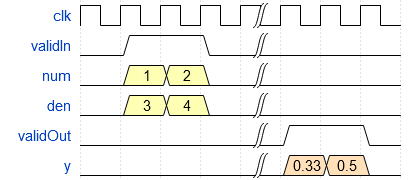
Implement Hardware-Efficient Real Divide HDL Optimized
How to use the Real Divide HDL Optimized block.
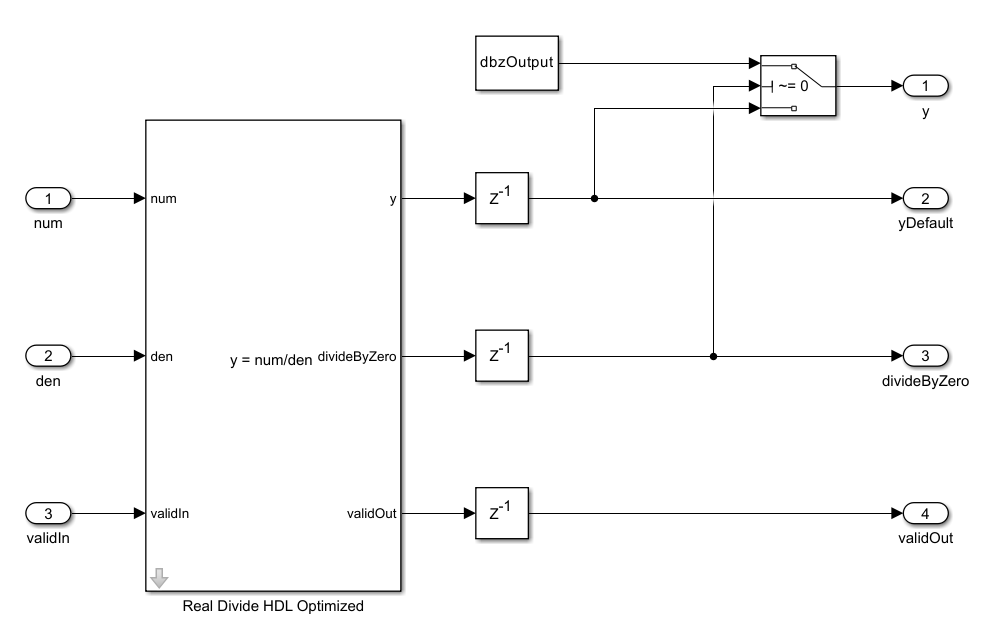
Customize Output Value of Real Divide HDL Optimized Block When Denominator Is Zero
Use the divideByZero port to customize the value of the block output when division by zero occurs.

How to Set CORDIC Input Word Length and Maximum Shift Value to Achieve Desired Precision
Provides a starting point for the input data type and number of iterations or maximum shift value required for the CORDIC algorithm to achieve a desired accuracy.
Limitations
Data type override is not supported for the Real Divide HDL Optimized block.
Ports
Input
Output
Parameters
Tips
The blocks Divide by Constant HDL Optimized, Real Divide HDL Optimized, and Complex Divide HDL Optimized all perform the division operation and generate optimized HDL code.
Real Divide HDL Optimized and Complex Divide HDL Optimized are based on a CORIDC algorithm. These blocks accept a wide variety of inputs, but will result in greater latency.
Divide by Constant HDL Optimized accepts only real inputs and a constant divisor. Use of this block consumes DSP slices, but will complete the division operation in fewer cycles and at a higher clock rate.
The behaviors of the Real Divide HDL Optimized and Complex Divide HDL Optimized blocks are equivalent to
when the inputs[y,dbz] = embblk.divide.cordicDivide(num,den,OutputType,maximumShiftValue)
numanddenare real or complex values, respectively. If the input data type is fixed point with binary-point scaling, the function and blocks produce bit-exact results. If the input data type is floating point, the function and the block can have small numerical differences.
Algorithms
Because of its fully pipelined nature, the Real Divide HDL Optimized block is able to accept input data on any cycle, including consecutive cycles. To send input data to the block, the validIn signal must be true. When the block has finished the computation and is ready to send the output, it will change validOut to true for one clock cycle. For inputs sent on consecutive cycles, validOut will also be set to true on consecutive cycles. Both the numerator and the denominator must be sent together on the same cycle.
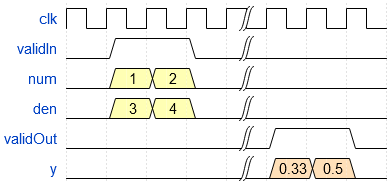
The latency depends on the input data type, the number of iterations per pipeline register, and the maximum shift value of hyperbolic vectoring CORDIC, as summarized in the table. In the table:
The word length of the inputs num and den can differ.
wl = max(num.WordLength + ~issigned(num), den.WordLength + ~issigned(den))When the Automatically select CORDIC maximum shift value based on input word length is set to
on, thenmaximumShiftValue = wl - 1. When the Automatically select CORDIC maximum shift value based on input word length is set tooff, thenmaximumShiftValueis specified by the CORDIC maximum shift value parameter.
| Input Type | Latency |
|---|---|
Fixed point or scaled double |
|
Floating point | 0 |
References
[1] Volder, Jack E. “The CORDIC Trigonometric Computing Technique.” IRE Transactions on Electronic Computers EC-8, no. 3 (Sept. 1959): 330–334.
[2] Andraka, Ray. “A Survey of CORDIC Algorithm for FPGA Based Computers.” In Proceedings of the 1998 ACM/SIGDA Sixth International Symposium on Field Programmable Gate Arrays, 191–200. https://dl.acm.org/doi/10.1145/275107.275139.
[3] Walther, J.S. “A Unified Algorithm for Elementary Functions.” In Proceedings of the May 18-20, 1971 Spring Joint Computer Conference, 379–386. https://dl.acm.org/doi/10.1145/1478786.1478840.
[4] Schelin, Charles W. “Calculator Function Approximation.” The American Mathematical Monthly, no. 5 (May 1983): 317–325. https://doi.org/10.2307/2975781.