CORDIC Square Root HDL Optimized

Libraries:
Fixed-Point Designer HDL Support /
Math Operations
Description
The CORDIC Square Root HDL Optimized block returns the square root of
u, computed using a CORDIC-based implementation optimized for HDL code
generation.
Examples
This example shows how to use the CORDIC Square Root HDL Optimized block to compute the square root of real non-negative scalars.
CORDIC-Based Square Root
The CORDIC Square Root HDL Optimized block uses a CORDIC algorithm in hyperbolic vectoring mode to compute the approximation of square root (see Compute Square Root Using CORDIC). This CORDIC-based algorithm is different from the Simulink® Sqrt block, which uses bisection and Newton-Raphson methods. The algorithm in the CORDIC Square Root HDL Optimized block requires only iterative shift-add operations.
I/O Interface
The CORDIC Square Root HDL Optimized block is fully-pipelined. It can accept input data on any cycle, including on consecutive clock cycles. Use validIn to indicate a valid input. When the block has finished the computation, it will change validOut to true for one clock cycle. For inputs sent on consecutive clock cycles, validOut will also be set to true on consecutive clock cycles.
Customizable CORDIC Maximum Shift Value and Number of Iterations Per Pipeline Register
This block uses iterative normalization and CORDIC algorithms. If the input is fixed point or scaled doubles, it uses multiple steps for computation. The normalization uses nextpow2(u.WordLength) iterations. The number of CORDIC iterations depends on the CORDIC maximum shift value. A larger word length can provide higher resolution but needs more iterations to process. This block can perform multiple iterations per pipeline stage. This results in smaller latency at cost of longer critical path in the generated HDL design.
For example, if the word length of the input u is 16, normalization requires 4 iterations. If the Automatically select CORDIC maximum shift value based on input word length parameter is selected, this block uses 16 - 1 = 15 as the CORDIC maximum shift value in the computation and it requires 17 iterations. The total number of iterations is 4 + 17 = 21 and the latency of the block is 2 + ceil(total number of iterations/nIterPerReg). If the number of iterations per pipeline register is set to 1, then the block latency is 23; if the number of iterations per pipeline register is set to 2, then the block latency is 13; etc. If the number of iterations per pipeline register is greater than or equal to the total number of required iterations, the block performs all iterations in one pipeline stage and the total latency is minimized to 3.
The total number of iterations and block latency can be calculated using the embblk.latency.cordicSqrtHDLOptimizedLatency function.
If the input is floating point, the block latency is 0.
Define Simulation Parameters
Specify the number of input samples.
numSamples = 10;
Specify the data type as fixed, scaledDouble, single, or double.
DT =  'fixed';
'fixed';For fixed-point data type, specify the word length and fraction length.
wordLength = 16; FractionLength = 10;
If the Automatically select CORDIC maximum shift value based on input word length parameter is not selected, define the maximum CORDIC shift value. For fixed point data types, this value cannot exceed wordLength - 1.
autoMaxVal =  "on";
maximumShiftValue = wordLength - 1;
"on";
maximumShiftValue = wordLength - 1;Generate Input Data
Generate input data u. The input value must be a real non-negative scalar.
rng('default');
u = abs(randn(1,numSamples));Cast to Selected Data Type
Cast the input data u to the selected data type.
switch lower(DT) case 'fixed' u = cast(u,'like',fi([],1,wordLength,FractionLength)); case 'scaleddouble' u = cast(u,'like',fi([],1,wordLength,FractionLength),'DataType','ScaledDouble'); case 'single' u = single(u); case 'double' u = double(u); otherwise u = double(u); end
Configure Block Pipeline
Check how many iterations the block requires for the selected data type.
[~, totalIterations] = embblk.latency.cordicSqrtHDLOptimizedLatency(u,1,maximumShiftValue)
totalIterations = 21
Define the number of iterations to be performed in one pipeline stage.
nIterPerReg = 1;
Open the Model
Open the CORDICSquareRootModel model.
model = 'CORDICSquareRootModel';
open_system(model);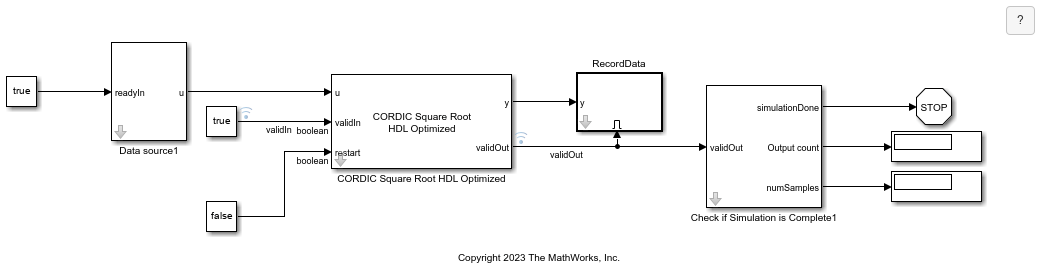
Simulate the Model
Configure the model workspace and run the simulation.
fixed.example.setModelWorkspace(model,'u',u,'numSamples',numSamples,'maximumShiftValue',maximumShiftValue,... 'nIterPerReg',nIterPerReg); set_param([model,'/CORDIC Square Root HDL Optimized'],'autoMaximumShiftVal',autoMaxVal); out = sim(model);
Verify Output Solutions
Compare the fixed-point result from the CORDIC Square Root HDL Optimized block with the floating-point result from the MATLAB® sqrt function.
yBuiltIn = sqrt(double(u))'; y = out.y(1:numSamples); absError = (double(y)-yBuiltIn)
absError = 10×1
10-3 ×
-0.1450
-0.7312
0.0029
-0.8692
0.2197
-0.9328
-0.2752
-0.5076
-0.9682
-0.1284
Block Latency
The block latency is the number of clock cycles between a successful input and when the corresponding output becomes valid. The latency of this block depends on the datatype, CORDIC maximum shift value, and Number of iterations per pipeline register.
Calculate the expected latency and total number of iterations. The CORDIC maximum shift value can be empty if the Automatically select CORDIC maximum shift value based on input word length parameter parameter is selected.
[explatency, ~] = embblk.latency.cordicSqrtHDLOptimizedLatency(u,nIterPerReg,maximumShiftValue)
explatency = 23
Retrieve block latency from the simulation.
tDataIn = find(out.logsout.get('validIn').Values.Data == 1); tDataOut = find(out.logsout.get('validOut').Values.Data == 1); actualLatency = tDataOut(1:numSamples) - tDataIn(1:numSamples)
actualLatency = 10×1
23
23
23
23
23
23
23
23
23
23
Ports
Input
Output
Parameters
Algorithms
Because of its fully pipelined nature, the CORDIC Square Root HDL
Optimized block is able to accept input data on any cycle, including consecutive
clock cycles. To send input data to the block, the validIn signal must be
true. When the block has finished the computation and is ready to send
the output, it will change validOut to true for one clock
cycle. For inputs set on consecutive cycles, validOut will also be set to
true on consecutive cycles.
The latency of the block is defined from the input to the corresponding output. For
example in the figure below, from In1 to Out1,
In2 to Out2, In3 to
Out3, etc.

Use the embblk.latency.cordicSqrtHDLOptimizedLatency function to calculate the latency
of the block and total number of iterations of the block.
References
[1] Volder, Jack E. “The CORDIC Trigonometric Computing Technique.” IRE Transactions on Electronic Computers EC-8, no. 3 (Sept. 1959): 330–334.
[2] Andraka, Ray. “A Survey of CORDIC Algorithm for FPGA Based Computers.” In Proceedings of the 1998 ACM/SIGDA Sixth International Symposium on Field Programmable Gate Arrays, 191–200. https://dl.acm.org/doi/10.1145/275107.275139.
[3] Walther, J.S. “A Unified Algorithm for Elementary Functions.” In Proceedings of the May 18-20, 1971 Spring Joint Computer Conference, 379–386. https://dl.acm.org/doi/10.1145/1478786.1478840.
[4] Schelin, Charles W. “Calculator Function Approximation.” The American Mathematical Monthly, no. 5 (May 1983): 317–325. https://doi.org/10.2307/2975781.
Extended Capabilities
Version History
Introduced in R2024a