rocmetrics
Receiver operating characteristic (ROC) curve and performance metrics for binary and multiclass classifiers
Since R2022b
Description
Create a rocmetrics object to evaluate the performance of a classification model using receiver operating characteristic (ROC) curves or other performance metrics. rocmetrics supports both binary and multiclass problems.
For each class, rocmetrics computes performance metrics for a one-versus-all ROC curve. You can compute metrics for an average ROC curve by
using the average function. After
computing metrics for ROC curves, you can plot them by using the plot function.
By default, rocmetrics computes the false positive rates (FPR) and the true
positive rates (TPR) to obtain a ROC curve. You can compute additional metrics by specifying
the AdditionalMetrics
name-value argument when you create an object or by calling the addMetrics function
after you create an object. A rocmetrics object stores the computed metrics
in the Metrics
properties.
In R2024b: You can find the area under the ROC curve (AUC) using the auc function.
rocmetrics computes pointwise confidence intervals for the performance
metrics when you set the NumBootstraps value to
a positive integer or when you specify cross-validated data for the true class labels
(Labels), classification
scores (Scores), and
observation weights (Weights). For details,
see Pointwise Confidence Intervals.
Using confidence intervals
requires Statistics and Machine Learning Toolbox™.
Creation
Description
rocObj = rocmetrics(Labels,Scores,ClassNames)rocmetrics object using the true class labels in
Labels and the classification scores in
Scores. Specify Labels as a vector of length n,
and specify Scores as a matrix of size
n-by-K, where n is the number
of observations, and K is the number of classes.
ClassNames specifies the column order in
Scores.
The Metrics property
contains the performance metrics for each class for which you specify
Scores and ClassNames.
If you specify cross-validated data in Labels and
Scores as cell arrays, then rocmetrics computes
confidence intervals for the performance metrics. Using cross-validated data
requires Statistics and Machine Learning Toolbox.
rocObj = rocmetrics(___,Name=Value)Prior="uniform" sets all class probabilities to be
equal.
Input Arguments
Name-Value Arguments
Properties
Object Functions
addMetrics | Compute additional classification performance metrics |
auc | Area under the ROC curve or area under the PR (precision-recall) curve |
average | Compute performance metrics for average receiver operating characteristic (ROC) curve in multiclass problem |
modelOperatingPoint | Operating point of rocmetrics object |
plot | Plot receiver operating characteristic (ROC) curves and other performance curves |
Examples
Load a sample of predicted classification scores and true labels for a classification problem.
load('flowersDataResponses.mat')trueLabels is the true labels for an image classification problem and scores is the softmax prediction scores. scores is an N-by-K array where N is the number of observations and K is the number of classes.
trueLabels = flowersData.trueLabels; scores = flowersData.scores;
Load the class names. The column order of scores follows the class order stored in classNames.
classNames = flowersData.classNames;
Create a rocmetrics object by using the true labels in trueLabels and the classification scores in scores. Specify the column order of scores using classNames.
rocObj = rocmetrics(trueLabels,scores,classNames);
rocObj is a rocmetrics object that stores performance metrics for each class in the property. Compute the AUC for all the model classes by calling auc on the object.
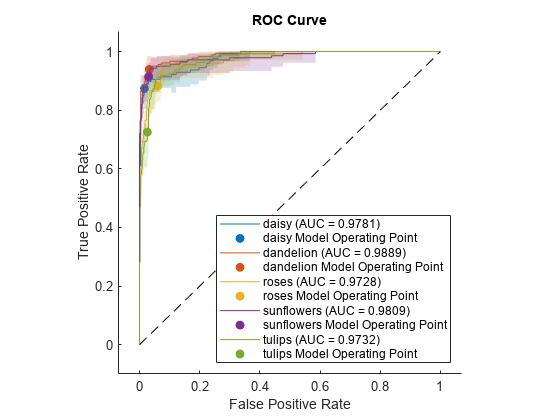
a = auc(rocObj)
a = 1×5 single row vector
0.9781 0.9889 0.9728 0.9809 0.9732
Plot the ROC curve for each class. The plot function also returns the AUC values for the classes.
plot(rocObj)

The filled circle markers indicate the model operating points. The legend displays the class name and AUC value for each curve.
Plot the macro average ROC curve.
plot(rocObj,AverageCurveType=["macro"],ClassNames=[])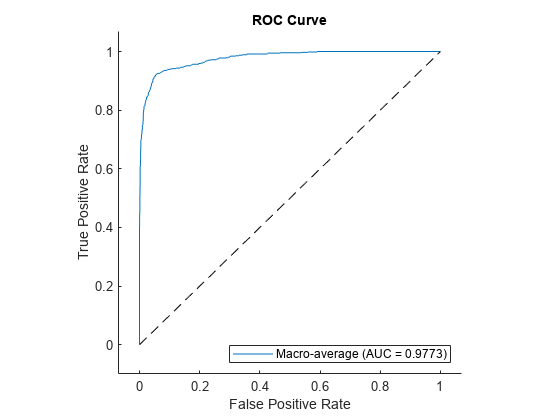
Compute the confidence intervals for FPR and TPR for fixed threshold values by using bootstrap samples, and plot the confidence intervals for TPR on the ROC curve by using the plot function. This examples requires Statistics and Machine Learning Toolbox™.
Load a sample of true labels and the prediction scores for a classification problem. For this example, there are five classes: daisy, dandelion, roses, sunflowers, and tulips. The class names are stored in classNames. The scores are the softmax prediction scores generated using the predict function. scores is an N-by-K array where N is the number of observations and K is the number of classes. The column order of scores follows the class order stored in classNames.
load('flowersDataResponses.mat')
scores = flowersData.scores;
trueLabels = flowersData.trueLabels;
predLabels = flowersData.predictedLabels;
classNames = flowersData.classNames;Create a rocmetrics object by using the true labels in trueLabels and the classification scores in scores. Specify the column order of scores using classNames. Specify NumBootstraps as 100 to use 100 bootstrap samples to compute the confidence intervals.
rocObj = rocmetrics(trueLabels,scores,classNames,NumBootstraps=100);
Find the rows for the second class in the table of the Metrics property, and display the first eight rows.
idx = rocObj.Metrics.ClassName ==classNames(2); head(rocObj.Metrics(idx,:))
ClassName Threshold FalsePositiveRate TruePositiveRate
_________ _________ _________________ _____________________________
dandelion 1 0 0 0 0 0 0
dandelion 1 0 0 0 0.23889 0.17858 0.31326
dandelion 1 0 0 0 0.26111 0.20107 0.34007
dandelion 1 0 0 0 0.27222 0.21829 0.35778
dandelion 1 0 0 0 0.28889 0.22739 0.36583
dandelion 1 0 0 0 0.29444 0.23682 0.41685
dandelion 1 0 0 0 0.3 0.24296 0.42567
dandelion 1 0 0 0 0.31111 0.24964 0.42614
Each row of the table contains the metric value and its confidence intervals for FPR and TPR for a fixed threshold value. The Threshold variable is a column vector, and the FalsePositiveRate and TruePositiveRate variables are three-column matrices. The first column of the matrices corresponds to the metric values, and the second and third columns correspond to the lower and upper bounds, respectively.
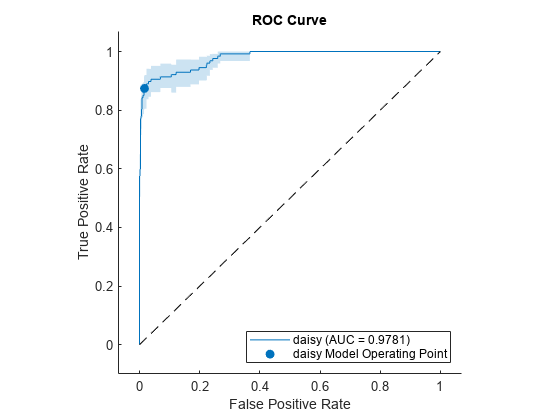
Plot the ROC curve and the confidence intervals for TPR. Specify ShowConfidenceIntervals=true to show the confidence intervals.
plot(rocObj,ShowConfidenceIntervals=true)
The shaded area around the ROC curve indicates the confidence intervals. The confidence intervals represent the uncertainty of the curve due to the variance in the data set for the trained model.
Specify one class to plot by using the ClassNames name-value argument.
plot(rocObj,ShowConfidenceIntervals=true,ClassNames="daisy")