Quantization
Quantize the weights, biases, and activations of layers to reduced-precision scaled integer data types. You can then generate C/C++, CUDA®, or HDL code from this quantized network for GPU, FPGA, or CPU deployment.
For a detailed overview of the compression techniques available in Deep Learning Toolbox™ Model Compression Library, see Reduce Memory Footprint of Deep Neural Networks.
Functions
dlquantizer | Quantize a deep neural network to 8-bit scaled integer data types |
dlquantizationOptions | Options for quantizing a trained deep neural network |
prepareNetwork | Prepare deep neural network for quantization (Since R2024b) |
calibrate | Simulate and collect ranges of a deep neural network |
quantize | Quantize deep neural network (Since R2022a) |
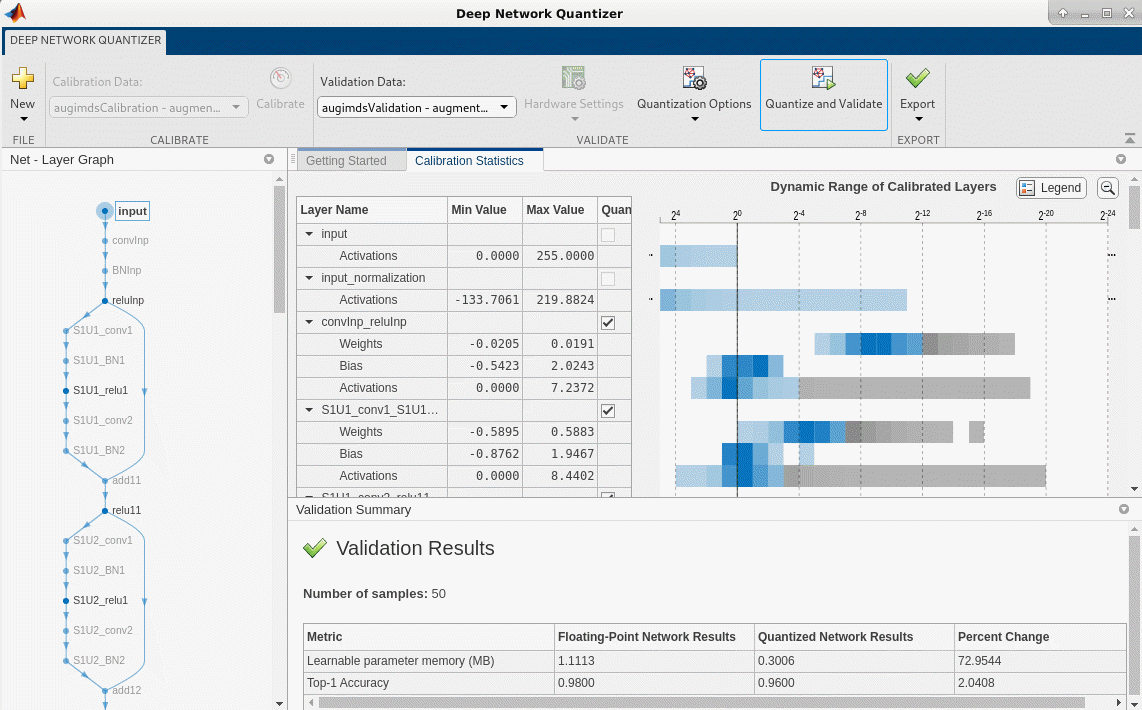
validate | Quantize and validate a deep neural network |
quantizationDetails | Display quantization details for a neural network (Since R2022a) |
estimateNetworkMetrics | Estimate network metrics for specific layers of a neural network (Since R2022a) |
equalizeLayers | Equalize layer parameters of deep neural network (Since R2022b) |
exportNetworkToSimulink | Generate Simulink model that contains deep learning layer blocks and subsystems that correspond to deep learning layer objects (Since R2024b) |
Apps
| Deep Network Quantizer | Quantize deep neural network to 8-bit scaled integer data types |
Topics
Understanding Quantization
- Quantization of Deep Neural Networks
Learn about deep learning quantization tools and workflows. - Data Types and Scaling for Quantization of Deep Neural Networks
Understand effects of quantization and how to visualize dynamic ranges of network convolution layers.
Pre-Deployment Workflows
- Prepare Data for Quantizing Networks
Learn about supported data formats for quantization workflows. - Quantize Multiple-Input Network Using Image and Feature Data
Quantize a network with multiple inputs. - Export Quantized Networks to Simulink and Generate Code
Export a quantized neural network to Simulink and generate code from the exported model. - Quantization-Aware Training with Pseudo-Quantization Noise
Perform quantization-aware training with pseudo-quantization noise on the MobileNet-V2 network. (Since R2026a)
Deployment
- Quantize Semantic Segmentation Network and Generate CUDA Code
Quantize a convolutional neural network trained for semantic segmentation and generate CUDA code. - Classify Images on FPGA by Using Quantized GoogLeNet Network (Deep Learning HDL Toolbox)
This example shows how to use the Deep Learning HDL Toolbox™ to deploy a quantized GoogleNet network to classify an image. - Compress Image Classification Network for Deployment to Resource-Constrained Embedded Devices
Reduce the memory footprint and computation requirements of an image classification network for deployment to resource-constrained embedded devices such as the Raspberry Pi®.
Considerations
- Quantization Workflow System Requirements
See what products are required for the quantization of deep neural networks. - Supported Layers for Quantization
Learn which deep neural network layers are supported for quantization.
Featured Examples
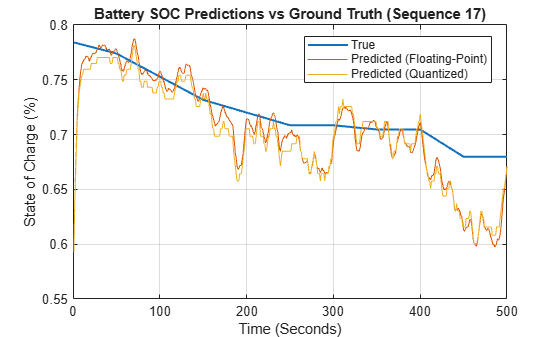
Quantize Deep Learning Network for Battery State of Charge Estimation
Quantize recurrent neural network trained for battery state of charge estimation.

Prune and Quantize Convolutional Neural Network for Speech Recognition
Compress a convolutional neural network (CNN) to prepare it for deployment on an embedded system.
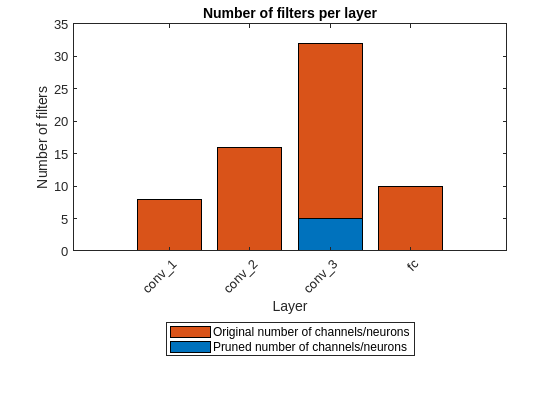
Parameter Pruning and Quantization of Image Classification Network
Use parameter pruning and quantization to reduce network size.

Prune and Quantize Semantic Segmentation Network
Reduce the memory footprint of a semantic segmentation network and speed-up inference by compressing the network using pruning and quantization.

Quantize Layers in Object Detectors and Generate CUDA Code
Generate CUDA® code for an SSD vehicle detector and a YOLO v2 vehicle detector that performs inference computations in 8-bit integers for the convolutional layers.
Quantize Residual Network Trained for Image Classification and Generate CUDA Code
Quantize the learnable parameters in the convolution layers of a deep learning neural network that has residual connections and has been trained for image classification with CIFAR-10 data.