Get Started with Network Compression
Use Deep Learning Toolbox together with the Deep Learning Toolbox Model Compression Library support package to reduce the memory footprint and computational requirements of a deep neural network:
Prune filters from convolution layers by using first-order Taylor approximation.
Project layers by performing principal component analysis (PCA) on the layer activations.
Quantize the weights, biases, and activations of layers to reduced precision scaled integer data types.
You can then generate code from the compressed network to deploy to your desired hardware.

Topics
- Reduce Memory Footprint of Deep Neural Networks
Learn about neural network compression techniques, including pruning, projection, and quantization.
Featured Examples
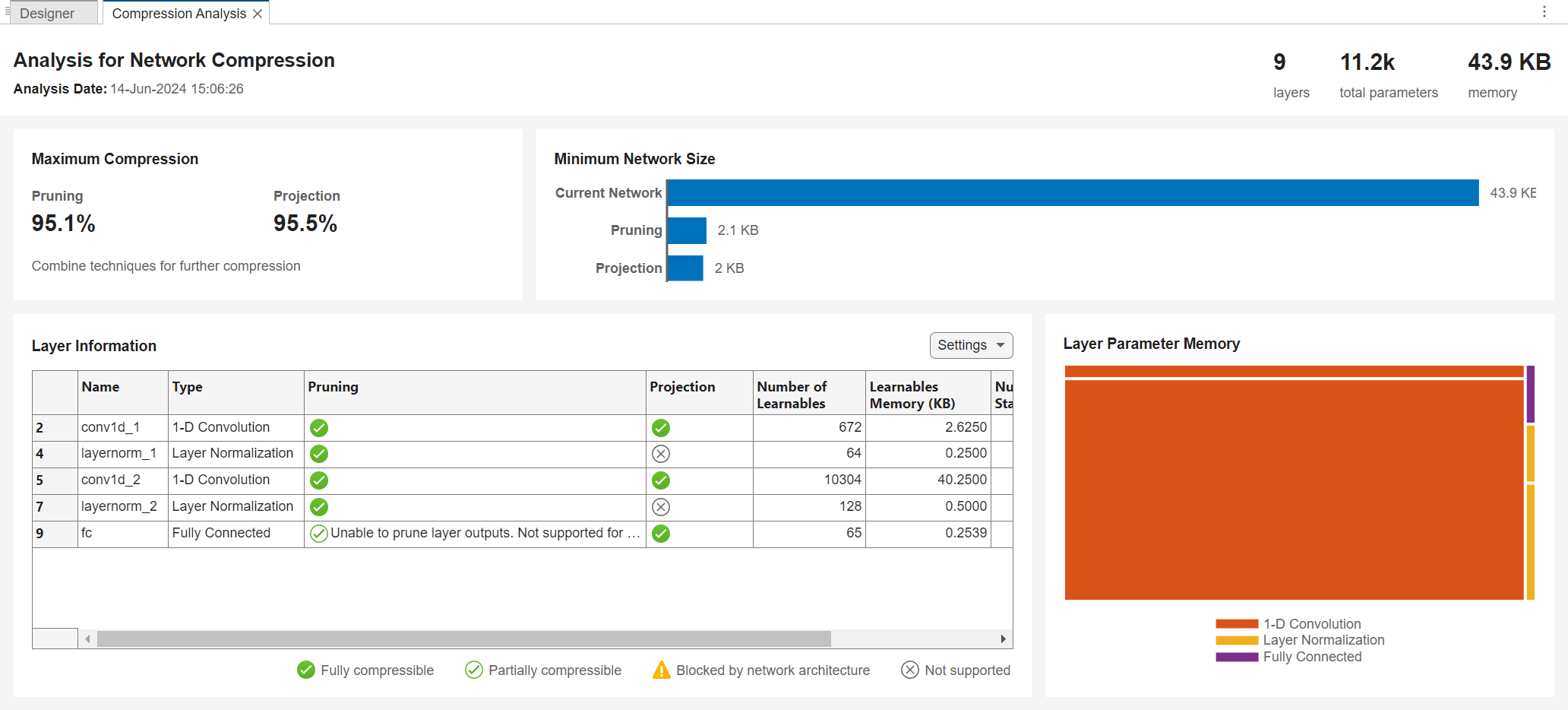
Analyze and Compress 1-D Convolutional Neural Network
Analyze 1-D convolutional network for compression and compress it using Taylor pruning and projection.
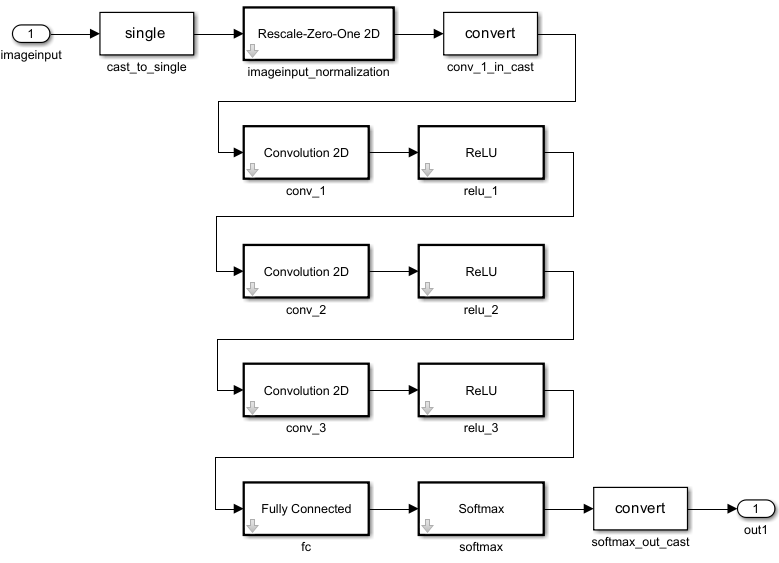
Export Quantized Networks to Simulink and Generate Code
Export a quantized neural network to Simulink and generate code from the exported model.

Prune Neural Network with Memory Requirement
Compress a neural network to a specific size using Taylor pruning.

Prune Neural Network with Accuracy Requirement
Compress a neural network with a minimum accuracy requirement using Taylor pruning.