Getting Started with SSD Multibox Detection
The single shot multibox detector (SSD) uses a single stage object detection network that merges detections predicted from multiscale features. The SSD is faster than two-stage detectors, such as the Faster R-CNN detector, and can localize objects more accurately compared to single-scale feature detectors, such as the YOLO v2 detector.
The SSD runs a deep learning CNN on an input image to produce network predictions from multiple feature maps. The object detector gathers and decodes predictions to generate bounding boxes.

Detect Objects in the Image
SSD returns the locations of detected objects as a set of bounding boxes. The SSD predicts these two attributes for each anchor box.
Anchor box offsets — Refine the anchor box position.
Class probability — Predict the class label assigned to each anchor box.
This figure shows predefined anchor boxes (the dotted lines) at each location in a feature map and the refined location after offsets are applied. Matched boxes with a class are in blue and orange. For more details, see Anchor Boxes for Object Detection.

Design an SSD Detection Network
You can design a custom SSD model programmatically by using the ssdObjectDetector function.
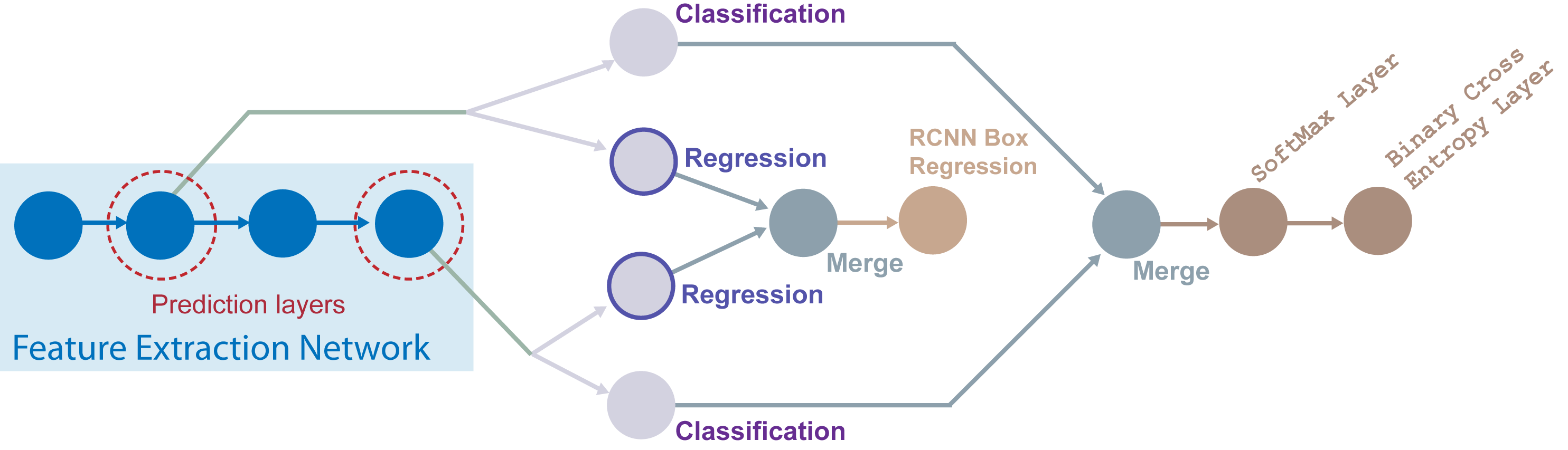
To design an SSD Multibox detection network, follow these steps.
Start the model with a feature extractor network, which can be a pretrained or untrained CNN.
Select prediction layers from the feature extraction network. Any layer from the feature extraction network can be used as a prediction layer. To leverage the benefits of using multiscale features for object detection, choose feature maps of different sizes.
Specify the names of the prediction layers as the detection network source input to the
ssdObjectDetectorobject. Also, specify the names of the classes and the anchor boxes as inputs to configure the detector for training.
The ssdObjectDetector object connects the outputs of the prediction
layers to a classification branch and to a regression branch. The classification branch
predicts the class for each tiled anchor box. The regression branch predicts anchor box offsets.
The
ssdObjectDetectorobject combines the outputs of the classification branches from all of the prediction layers by using a merge layer. Then, the output from the merge layer of the classification branch is connected to a softmax layer followed by a binary cross-entropy layer. The classification branch computes classification loss by using binary cross-entropy function.Similarly, the
ssdObjectDetectorobject combines the outputs of the regression branches from all the prediction layers by using a merge layer. Then, the output from the merge layer of the regression branch is connected to a bounding box regression layer. The regression branch computes the bounding box loss by using smooth L1 function.
Train an Object Detector and Detect Objects with an SSD Model
To train an SSD object detection network, use the trainSSDObjectDetector function. For more information, see Train SSD Object Detector.
Detect objects in an image by using the detect
function. For an example, see Object Detection Using SSD Deep Learning.
Transfer Learning
With transfer learning, you can use a pretrained CNN as the feature extractor in an
SSD detection network. Use the ssdObjectDetector function to create an SSD detection network from a
pretrained CNN, such as MobileNet-v2. For a list of pretrained CNNs, see Pretrained Deep Neural Networks (Deep Learning Toolbox).
Code Generation
To learn how to generate CUDA® code using the SSD object detector (created using the ssdObjectDetector object), see Code Generation for Object Detection by Using Single Shot Multibox Detector.
Label Training Data for Deep Learning
You can use the Image Labeler,
Video Labeler,
or Ground Truth Labeler (Automated Driving Toolbox) apps to interactively
label pixels and export label data for training. The apps can also be used to label
rectangular regions of interest (ROIs) for object detection, scene labels for image
classification, and pixels for semantic segmentation. To create training data from any
of the labelers exported ground truth object, you can use the objectDetectorTrainingData or pixelLabelTrainingData functions. For more details, see Training Data for Object Detection and Semantic Segmentation.
References
[1] Liu, Wei, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C. Berg. "SSD: Single Shot MultiBox Detector." In Computer Vision – ECCV 2016, edited by Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, 9905:21-37. Cham: Springer International Publishing, 2016. https://doi.org/10.1007/978-3-319-46448-0_2.
See Also
Apps
- Image Labeler | Ground Truth Labeler (Automated Driving Toolbox) | Video Labeler | Deep Network Designer (Deep Learning Toolbox)
Objects
Functions
trainSSDObjectDetector|detect|analyzeNetwork(Deep Learning Toolbox)