ttest2
Two-sample t-test
Description
h = ttest2(x,y)x and y comes
from independent random samples from normal distributions with equal
means and equal but unknown variances, using the two-sample t-test.
The alternative hypothesis is that the data in x and y comes
from populations with unequal means. The result h is 1 if
the test rejects the null hypothesis at the 5% significance level,
and 0 otherwise.
h = ttest2(x,y,Name,Value)
Examples
Load the data set. Create vectors containing the first and second columns of the data matrix to represent students’ grades on two exams.
load examgrades
x = grades(:,1);
y = grades(:,2);Test the null hypothesis that the two data samples are from populations with equal means.
[h,p,ci,stats] = ttest2(x,y)
h = 0
p = 0.9867
ci = 2×1
-1.9438
1.9771
stats = struct with fields:
tstat: 0.0167
df: 238
sd: 7.7084
The returned value of h = 0 indicates that ttest2 does not reject the null hypothesis at the default 5% significance level.
Load the data set. Create vectors containing the first and second columns of the data matrix to represent students’ grades on two exams.
load examgrades
x = grades(:,1);
y = grades(:,2);Test the null hypothesis that the two data vectors are from populations with equal means, without assuming that the populations also have equal variances.
[h,p] = ttest2(x,y,'Vartype','unequal')
h = 0
p = 0.9867
The returned value of h = 0 indicates that ttest2 does not reject the null hypothesis at the default 5% significance level even if equal variances are not assumed.
Load the sample data. Create a categorical vector to label the vehicle mileage data according to the vehicle year.
load carbig.mat; decade = categorical(Model_Year < 80,[true,false],["70s","80s"]);
Create box plots of the mileage data for each decade.
boxchart(decade,MPG) xlabel("Decade") ylabel("Mileage")
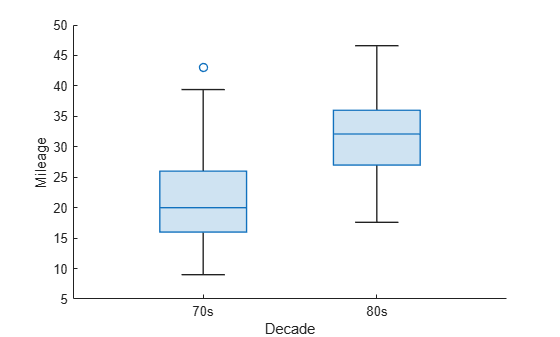
Create vectors from the mileage data for each decade. Use a left-tailed, two-sample t-test to test the null hypothesis that the data comes from populations with equal means. Use the alternative hypothesis that the population mean for the mileage of cars made in the 1970s is less than the population mean for the mileage of cars made in the 1980s.
MPG70s = MPG(decade == "70s"); MPG80s = MPG(decade == "80s"); [h,~,~,stats] = ttest2(MPG70s,MPG80s,"Tail","left")
h = 1
stats = struct with fields:
tstat: -14.0630
df: 396
sd: 6.3910
The returned value of h = 1 indicates that ttest2 rejects the null hypothesis at the default significance level of 5%, in favor of the alternative hypothesis that the population mean for the mileage of cars made in the 1970s is less than the population mean for the mileage of cars made in the 1980s.
Plot the corresponding Student's t-distribution, the returned t-statistic, and the critical t-value. Calculate the critical t-value at the default confidence level of 95% by using tinv.
nu = stats.df; k = linspace(-15,15,300); tdistpdf = tpdf(k,nu); tval = stats.tstat
tval = -14.0630
tvalpdf = tpdf(tval,nu); tcrit = -tinv(0.95,nu)
tcrit = -1.6487
plot(k,tdistpdf) hold on scatter(tval,tvalpdf,"filled") xline(tcrit,"--") legend(["Student's t pdf","t-statistic", ... "Critical Cutoff"])
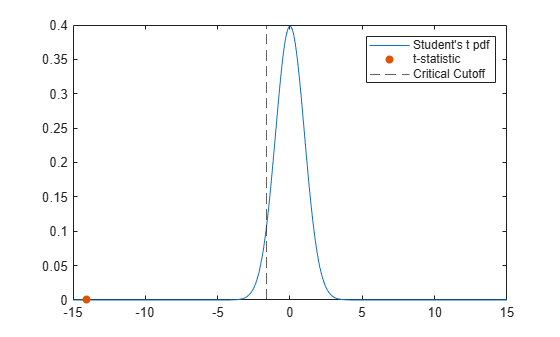
The orange dot represents the t-statistic and is located to the left of the dashed black line that represents the critical t-value.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
Use
sampsizepwrto calculate:The sample size that corresponds to specified power and parameter values;
The power achieved for a particular sample size, given the true parameter value;
The parameter value detectable with the specified sample size and power.
Extended Capabilities
Version History
Introduced before R2006a
See Also
ttest | ztest | sampsizepwr