unstack
Unstack data from input table or timetable into multiple variables of output table or timetable
Description
U = unstack(S,vars,ivar)vars specifies the variables to unstack. In general, the
output contains more variables, but fewer rows, than the input.
The input argument ivar specifies the
indicator variable. In each row of the input, the value of
the indicator variable indicates the corresponding variable of the output. The
unstack function aggregates data with matching indicator
values. Then it distributes the aggregated values across the variables of the
output.
The default aggregation method depends on the data type. For example, by default
unstack aggregates numeric data by summing it.
The input might have other variables not specified as vars or
ivar. The unstack function treats the
remaining variables differently in tables and timetables.
If
Sis a table, thenunstacktreats the remaining variables as grouping variables. Each unique combination of values in the grouping variables identifies a group of rows inSthat is unstacked into one row ofU.If
Sis a timetable, thenunstackdiscards the remaining variables. However,unstacktreats the vector of row times as a grouping variable.
You cannot unstack the row names of a table, or the row times of a timetable, or specify either as the indicator variable.
Examples
Load a table from the snowfall.mat sample file indicating the amount of snowfall in various towns for various storms. The table contains three snowfall entries for each storm, one for each town. It is in stacked format, with Storm and Town having the categorical data type. Table variables that have the categorical data type are useful as indicator variables and grouping variables.
load snowfall.mat
SS=12×3 table
Storm Town Snowfall
_____ _________ ________
3 Natick 0
3 Worcester 3
1 Natick 5
3 Boston 5
1 Boston 9
1 Worcester 10
4 Boston 12
2 Natick 13
4 Worcester 15
2 Worcester 16
4 Natick 17
2 Boston 21
Separate the variable Snowfall into three variables, one for each town indicated in the variable Town. The output table is in unstacked format. Each row in U contains data from rows in S that have the same value in the grouping variable Storm. The order of the unique values in Storm determines the row order of the data in U.
U = unstack(S,"Snowfall","Town")
U=4×4 table
Storm Boston Natick Worcester
_____ ______ ______ _________
3 5 0 3
1 9 5 10
4 12 17 15
2 21 13 16
The unstacked format can be more convenient for some types of analysis and display. For example, now it is more straightforward to plot snowfall amounts for each town. To make a scatter plot of the snowfall amounts in each town, use the scatter function.
scatter(U,"Storm",["Boston" "Natick" "Worcester"])
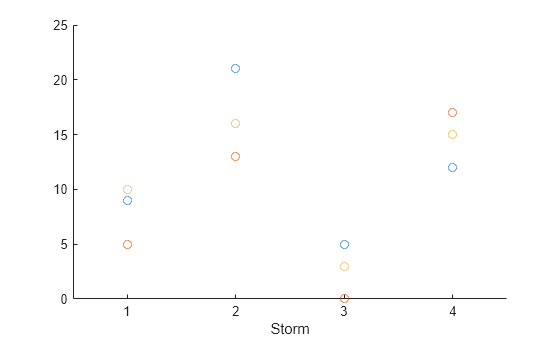
Unstack data and apply an aggregation function to multiple rows in the same group that have the same values in the indicator variable. Also return the index vector as the second argument. Use it to index into the original stacked input table.
Load a timetable from the stockPricesSmall.mat sample file containing data on the price of two stocks over two days. The Stock variable has the categorical data type because this timetable has a fixed set of stock names.
load stockPricesSmall.mat
SS=11×2 timetable
Date Stock Price
___________ ______ _____
12-Apr-2025 Stock1 60.35
12-Apr-2025 Stock2 27.68
12-Apr-2025 Stock1 64.19
12-Apr-2025 Stock2 25.47
12-Apr-2025 Stock2 28.11
12-Apr-2025 Stock2 27.98
15-Apr-2025 Stock1 63.85
15-Apr-2025 Stock2 27.55
15-Apr-2025 Stock2 26.43
15-Apr-2025 Stock1 65.73
15-Apr-2025 Stock2 25.94
S contains two prices for Stock1 during the first day and four prices for Stock2 during the first day.
Create a timetable that contains separate variables for each stock and one row for each day. Treat Date (the vector of row times) as the grouping variable and specify mean as the aggregation function. This operation unstacks prices from the Price variable, groups prices by date, and calculates the mean price for each stock on each day.
[U,is] = unstack(S,"Price","Stock", ... AggregationFunction=@mean)
U=2×2 timetable
Date Stock1 Stock2
___________ ______ ______
12-Apr-2025 62.27 27.31
15-Apr-2025 64.79 26.64
is = 2×1
1
7
The second output is identifies the index of the first value for each group of rows in S. For example, the first value for the group with the date April 15, 2025, is in the seventh row of S.
S(is(2),:)
ans=1×2 timetable
Date Stock Price
___________ ______ _____
15-Apr-2025 Stock1 63.85
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
You can specify more than one data variable of the input, and each variable becomes a set of unstacked data variables in the output. Use a vector of positive integers, a cell array or string array containing multiple variable names, or a logical vector to specify
vars. The one indicator variable, specified by the input argumentivar, applies to all data variables specifies byvars.
Extended Capabilities
Version History
Introduced in R2013bSee Also
Functions
stack|pivot|join|rowfun|varfun|splitapply|groupsummary