idTreeEnsemble
Decision tree ensemble mapping function for nonlinear ARX models (requires Statistics and Machine Learning Toolbox)
Since R2021b
Description
An idTreeEnsemble object implements a decision tree ensemble
model, and is a nonlinear mapping function for estimating nonlinear ARX models. This mapping
object incorporates regression tree ensembles that the mapping function creates using
Statistics and Machine Learning Toolbox™. Unlike most other mapping objects for idnlarx models, which typically contain offset, linear, and nonlinear components,
the idTreeEnsemble model contains only a nonlinear component.
![]()
Mathematically, the idTreeEnsemble object maps m
inputs x(t) =
[x1(t),x2(t),…,xm(t)]T
to a scalar output y(t) using a decision tree regression
ensemble model.
Here:
x(t) is an m-by-1 vector of inputs, or regressors.
y(t) is the scalar output.
For more information about creating regression tree ensembles, see fitrensemble (Statistics and Machine Learning Toolbox).
Use idTreeEnsemble as the value of the OutputFcn
property of an idnlarx model. For example, specify
idTreeEnsemble when you estimate an idnlarx model with the
following
command.
sys = nlarx(data,regressors,idTreeEnsemble)
nlarx estimates the model, it essentially estimates the parameters of the
idTreeEnsemble object.You can configure the idTreeEnsemble function to set options and fix
parameters. To modify the estimation options, set the option property in
E.EstimationOptions, where E is the
idTreeEnsemble object. For example, to change the fit method to
'lsboost-resampled', use E.EstimationOptions.FitMethod =
'lsboost-resampled'. To fix the values of an existing estimated
idTreeEnsemble during subsequent nlarx estimations,
set the Free property to false. To apply parallel
processing, set E.EstimationOptions.UseParallel to true.
Use evaluate to compute the output of the function for a given vector of regressor
inputs.
Creation
Description
E = idTreeEnsembleidTreeEnsemble object E with the default
estimation fit method of 'bag'. The number of regressor inputs is
determined during model estimation and the number of idTreeEnsemble
outputs is 1.
E = idTreeEnsemble(fitmethod)fitmethod.
Input Arguments
Properties
Examples
Load the data mrdamper. This data contains damping force (F) and velocity (V) information for a fluid damper, with a sample time of Ts.
load mrdamperCreate an iddata object data that uses F as the output and V as the input. Divide data into estimation and validation data sets ze and zv.
data = iddata(F,V,Ts); ze = data(1:3000); zv = data(3001:end);
Create an idTreeEnsemble mapping object E with default settings.
E = idTreeEnsemble;
Estimate a nonlinear ARX model sys that uses E for the output function.
sys = nlarx(ze,[16 16 0],E);
The model stores the estimated mapping object in the property sys.OutputFcn.
sys.OutputFcn
ans =
Regression Tree Ensemble
Inputs: y1(t-1), y1(t-2), y1(t-3), y1(t-4), y1(t-5), y1(t-6), y1(t-7), y1(t-8), y1(t-9), y1(t-10), y1(t-11), y1(t-12), y1(t-13), y1(t-14), y1(t-15), y1(t-16), u1(t), u1(t-1), u1(t-2), u1(t-3), u1(t-4), u1(t-5), u1(t-6), u1(t-7), u1(t-8), u1(t-9), u1(t-10), u1(t-11), u1(t-12), u1(t-13), u1(t-14), u1(t-15)
Output: y1(t)
Bagged Regression Tree Ensemble
Free: 1
EstimationOptions: 'Estimation option set'
Compare the model simulated output to the estimation data output.
compare(ze,sys)
Compare the model simulated output to the validation data output.
compare(zv,sys)
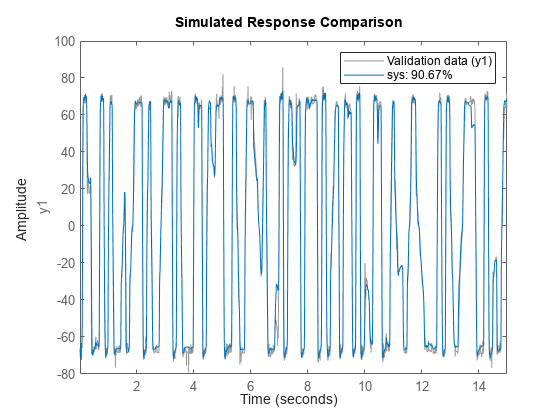
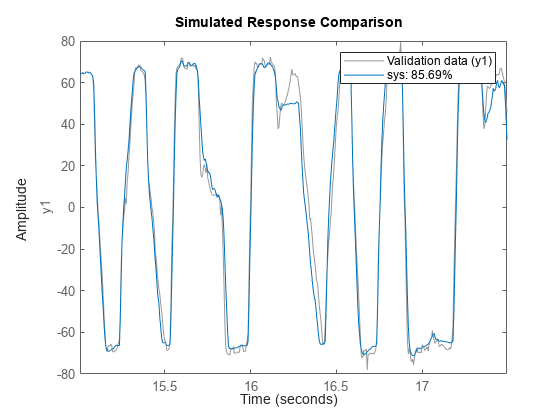
sys shows a good fit to both the estimation data and the validation data.
Extended Capabilities
Version History
Introduced in R2021bSee Also
nlarx | idnlarx | fitrensemble (Statistics and Machine Learning Toolbox) | evaluate
Topics
- Framework for Ensemble Learning (Statistics and Machine Learning Toolbox)
- Available Mapping Functions for Nonlinear ARX Models