Predict Chaotic Time-Series Using ANFIS
This example shows how to do chaotic time-series prediction using an adaptive neuro-fuzzy inference system (ANFIS).
Time Series Data
This example trains a fuzzy inference system to predict a time series generated by the following Mackey-Glass (MG) time-delay differential equation.
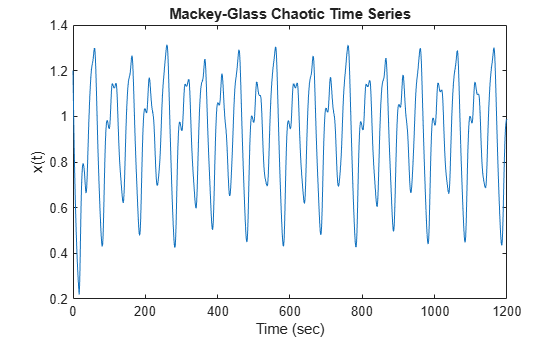
This time series is chaotic with no clearly defined period. The series does not converge or diverge, and the trajectory is highly sensitive to initial conditions. This benchmark problem is used in the neural network and fuzzy modeling research communities.
To obtain the time series value at integer points, the fourth-order Runge-Kutta method was used to find the numerical solution to the previous MG equation. It was assumed that , , and for . The result was saved in the file mgdata.dat.
Load and plot the MG time series.
load mgdata.dat time = mgdata(:,1); x = mgdata(:, 2); figure(1) plot(time,x) title("Mackey-Glass Chaotic Time Series") xlabel("Time (sec)") ylabel("x(t)")
Preprocess Data
In time-series prediction, you use known values of the time series up to point in time, , to predict the value at some point in the future, . The standard method for this type of prediction is to create a mapping from sample data points, sampled every units in time () to a predicted future value . Following the conventional settings for predicting the MG time series, set and . For each , the input training data is a four-column array of the following form.
The output training data corresponds to the trajectory prediction.
For each , ranging in values from 118 to 1117, there are 1000 input/output training samples. For this example, use the first 500 samples as training data (trnData) and the second 500 values as validation (valData). Each row of the training and validation data arrays contains one sample point where the first four columns contain the four-dimensional input and the fifth column contains the output .
Construct the training and validation data arrays.
for t = 118:1117 Data(t-117,:) = [x(t-18) x(t-12) x(t-6) x(t) x(t+6)]; end trnData = Data(1:500,:); valData = Data(501:end,:);
Build Initial Fuzzy System
Create an initial Sugeno FIS object for training using the genfis function with grid partitioning.
fis = genfis(trnData(:,1:end-1),trnData(:,end),... genfisOptions("GridPartition"));
The number of FIS inputs and outputs corresponds to the number of columns in the input and output training data, four and one, respectively.
By default, genfis creates two generalized bell membership functions for each of the four inputs. The initial membership functions for each variable are equally spaced and cover the whole input space.
figure tiledlayout nexttile plotmf(fis,"input",1) nexttile plotmf(fis,"input",2) nexttile plotmf(fis,"input",3) nexttile plotmf(fis,"input",4)
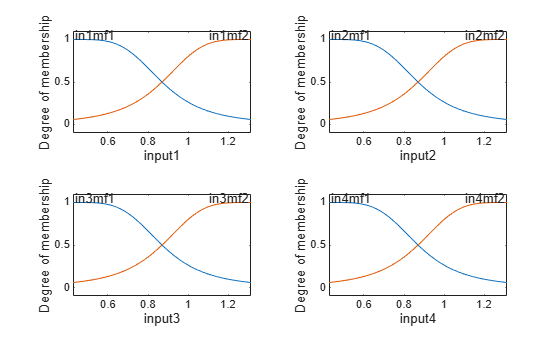
The generated FIS object contains = 16 fuzzy rules with 104 parameters (24 nonlinear parameters and 80 linear parameters). To achieve good generalization capability, it is important that the number of training data points be several times larger than the number parameters being estimated. In this case, the ratio between data and parameters is approximately five (500/104), which is a good balance between fitting parameters and training sample points.
Train ANFIS Model
To configure training options, create a tunefisOptions object, specifying the validation data.
options = tunefisOptions(Method="anfis");
options.MethodOptions.ValidationData = valData;Train the FIS using the specified training data and options.
[in,out] = getTunableSettings(fis); [fis1,summary] = tunefis(fis,[in;out],trnData(:,1:4),trnData(:,5),options);
ANFIS info: Number of nodes: 55 Number of linear parameters: 80 Number of nonlinear parameters: 24 Total number of parameters: 104 Number of training data pairs: 500 Number of checking data pairs: 500 Number of fuzzy rules: 16 Start training ANFIS ... 1 0.00296046 0.00292488 2 0.00290346 0.0028684 3 0.00285048 0.00281544 4 0.00280117 0.00276566 Step size increases to 0.011000 after epoch 5. 5 0.00275517 0.00271874 6 0.00271214 0.00267438 7 0.00266783 0.00262818 8 0.00262626 0.00258435 Step size increases to 0.012100 after epoch 9. 9 0.00258702 0.00254254 10 0.00254972 0.00250247 Designated epoch number reached. ANFIS training completed at epoch 10. Minimal training RMSE = 0.00254972 Minimal checking RMSE = 0.00250247
Extract the minimum training error and minimum validation error from the training summary. Also, extract the FIS for which the validation error was smallest.
trnError = summary.tuningOutputs.trainError; valError = summary.tuningOutputs.chkError; valFIS = summary.tuningOutputs.chkFIS;
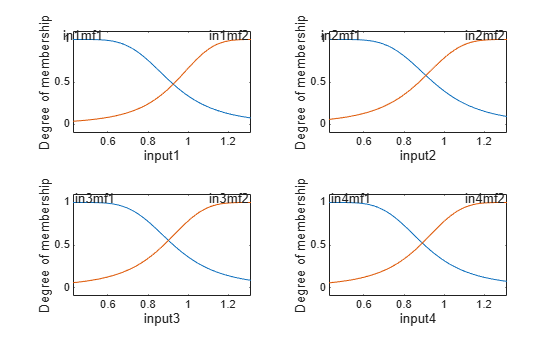
fis1 is the trained fuzzy inference system for the training epoch where the training error is smallest. Since you specified validation data, the fuzzy system with the minimum validation error, valFIS, is also returned. The FIS with the smallest validation error shows the best generalization beyond the training data.
Plots the membership functions for the trained system.
figure tiledlayout nexttile plotmf(valFIS,"input",1) nexttile plotmf(valFIS,"input",2) nexttile plotmf(valFIS,"input",3) nexttile plotmf(valFIS,"input",4)
Plot Errors Curves
Plot the training and validation error signals.
figure plot([trnError valError]) hold on plot([trnError valError],"o") legend("Training error","Validation error") xlabel("Epochs") ylabel("Root Mean Squared Error") title("Error Curves")
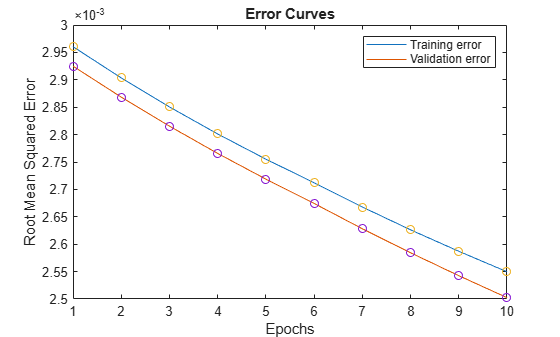
The training error is higher than the validation error in all epochs. This phenomenon is not uncommon in ANFIS learning or nonlinear regression in general; it might indicate that additional training could produce better training results.
Compare Original and Predicted Series
To check prediction capability of the trained system, evaluate the fuzzy system using the training and validation data, and plot the result alongside the original.
anfisOut = evalfis(valFIS,[trnData(:,1:4); valData(:,1:4)]); figure index = 125:1124; plot(time(index),[x(index) anfisOut]) xlabel("Time (sec)") title("MG Time Series and ANFIS Prediction")
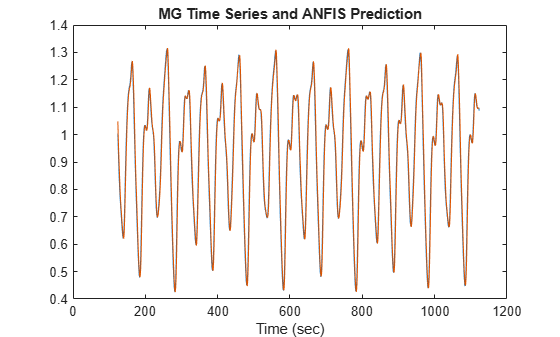
The predicted series is similar to the original series.
Calculate and plot the prediction error.
diff = x(index) - anfisOut; plot(time(index),diff) xlabel("Time (sec)") title("Prediction Errors")
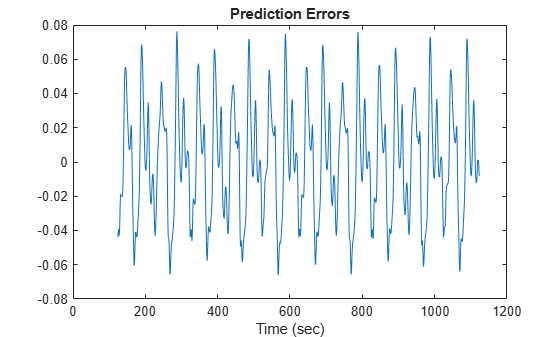
The scale of the prediction error plot is about one-hundredth of the scale of the time-series plot. In this example, you trained the system for only 10 epoch. Training for additional epochs can improve the training results.