TransposedConvolution2DLayer
Transposed 2-D convolution layer
Description
A transposed 2-D convolution layer upsamples two-dimensional feature maps.
This layer is sometimes incorrectly known as a "deconvolution" or "deconv" layer. This layer is the transpose of convolution and does not perform deconvolution.
Creation
Create a transposed convolution 2-D layer using transposedConv2dLayer.
Properties
Examples
Algorithms
A transposed 2-D convolution layer upsamples two-dimensional feature maps.
The standard convolution operation downsamples the input by applying sliding convolutional filters to the input. By flattening the input and output, you can express the convolution operation as for the convolution matrix C and bias vector B that can be derived from the layer weights and biases.
Similarly, the transposed convolution operation upsamples the input by applying sliding convolutional filters to the input. To upsample the input instead of downsampling using sliding filters, the layer zero-pads each edge of the input with padding that has the size of the corresponding filter edge size minus 1.
By flattening the input and output, the transposed convolution operation is equivalent to , where C and B denote the convolution matrix and bias vector for standard convolution derived from the layer weights and biases, respectively. This operation is equivalent to the backward function of a standard convolution layer.
This image shows a 3-by-3 filter upsampling 2-by-2 input. The lower map represents the input and the upper map represents the output. 1
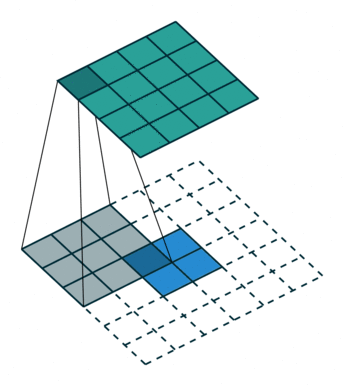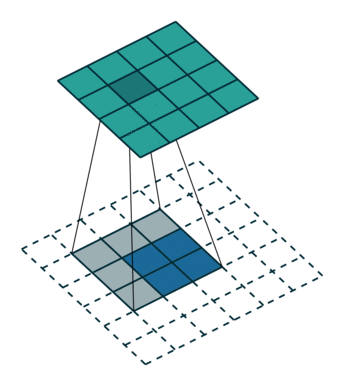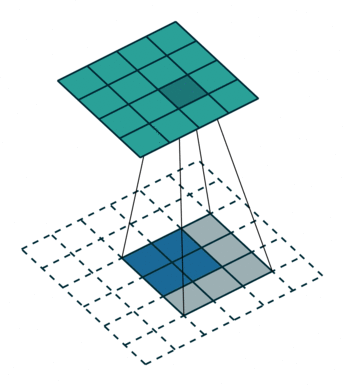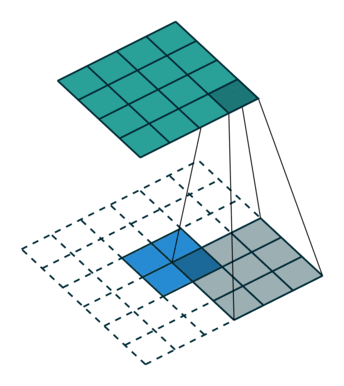
References
[1] Glorot, Xavier, and Yoshua Bengio. "Understanding the Difficulty of Training Deep Feedforward Neural Networks." In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, 249–356. Sardinia, Italy: AISTATS, 2010. https://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
[2] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification." In 2015 IEEE International Conference on Computer Vision (ICCV), 1026–34. Santiago, Chile: IEEE, 2015. https://doi.org/10.1109/ICCV.2015.123
Version History
Introduced in R2017b1 Image credit: Convolution arithmetic (License)