Accelerate Prototyping Workflow for Large Networks by Using Ethernet
This example shows how to deploy a deep learning network and obtain prediction results using the Ethernet connection to your target device. You can significantly speed up the deployment and prediction times for large deep learning networks by using Ethernet versus JTAG. This example shows the workflow on a ZCU102 SoC board. The example also works on the other boards supported by Deep Learning HDL Toolbox. See Supported Networks, Layers, Boards, and Tools.
Prerequisites
Xilinx ZCU102 SoC Development Kit. For help with board setup, see Guided SD Card Setup.
Deep Learning HDL Toolbox™ Support Package for Xilinx FPGA and SoC
Deep Learning HDL Toolbox™
Deep Learning Toolbox™ Model for ResNet-18 Network
Introduction
Deep Learning HDL Toolbox establishes a connection between the host computer and FPGA board to prototype deep learning networks on hardware. This connection is used to deploy deep learning networks and run predictions. The connection provides two services:
Programming the bitstream onto the FPGA
Communicating with the design running on FPGA from MATLAB
There are two hardware interfaces for establishing a connection between the host computer and FPGA board: JTAG and Ethernet.
JTAG Interface
The JTAG interface, programs the bitstream onto the FPGA over JTAG. The bitstream is not persistent through power cycles. You must reprogram the bitstream each time the FPGA is turned on.
MATLAB uses JTAG to control an AXI Master IP in the FPGA design, to communicate with the design running on the FPGA. You can use the AXI Master IP to read and write memory locations in the onboard memory and deep learning processor.
This figure shows the high-level architecture of the JTAG interface.
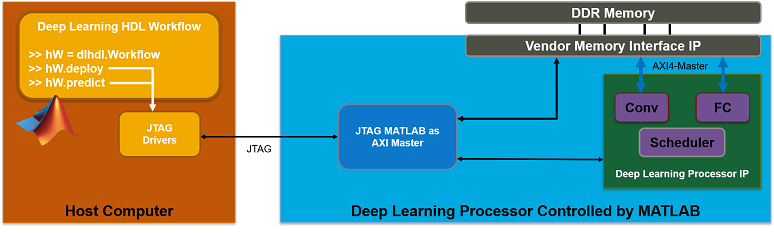
Ethernet Interface
The Ethernet interface leverages the ARM processor to send and receive information from the design running on the FPGA. The ARM processor runs on a Linux operating system. You can use the Linux operating system services to interact with the FPGA. When using the Ethernet interface, the bitstream is downloaded to the SD card. The bitstream is persistent through power cycles and is reprogrammed each time the FPGA is turned on. The ARM processor is configured with the correct device tree when the bitstream is programmed.
To communicate with the design running on the FPGA, MATLAB leverages the Ethernet connection between the host computer and ARM processor. The ARM processor runs a LIBIIO service, which communicates with a datamover IP in the FPGA design. The datamover IP is used for fast data transfers between the host computer and FPGA, which is useful when prototyping large deep learning networks that would have long transfer times over JTAG. The ARM processor generates the read and write transactions to access memory locations in both the onboard memory and deep learning processor.
The figure below shows the high-level architecture of the Ethernet interface.
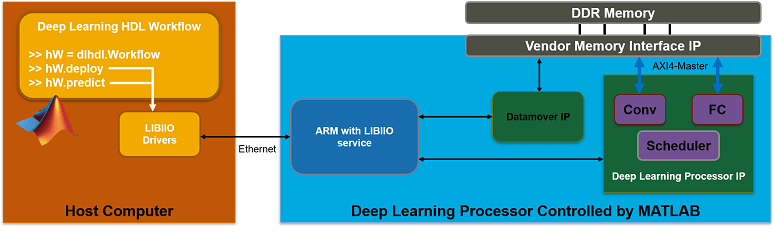
Load and Compile Deep Learning Network
This example uses the pretrained DAG network resnet18. This network is a larger network that has significant improvement in transfer time when deploying it to the FPGA by using Ethernet. To load resnet18, run the command:
net = resnet18;
The pretrained ResNet-18 network contains 71 layers including the input, convolution, batch normalization, ReLU, max pooling, addition, global average pooling, fully connected, and the softmax layers. To view the layers of the network enter:
analyzeNetwork(net);
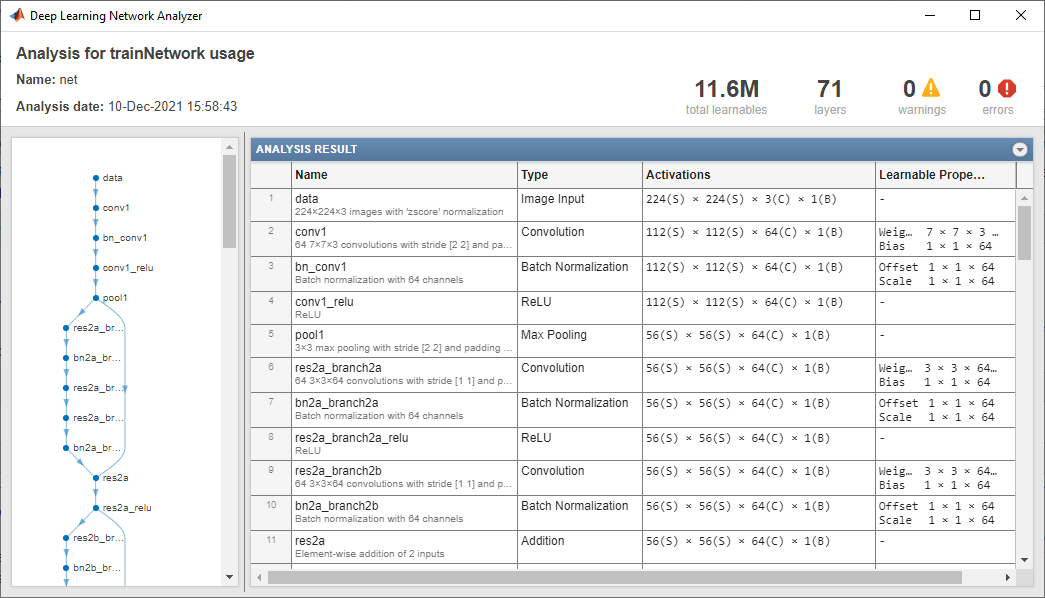
To deploy the deep learning network on the target FPGA board, create a dlhdl.Workflow object that has the pretrained network net as the network and the bitstream for your target FPGA board. This example uses the bitstream 'zcu102_single', which has single data type and is configured for the ZCU102 board. To run this example on a different board, use the bitstream for your board.
hW = dlhdl.Workflow('Network', net, 'Bitstream', 'zcu102_single');
Compile the resnet18 network for deployment to the FPGA.
compile(hW);
### Compiling network for Deep Learning FPGA prototyping ...
### Targeting FPGA bitstream zcu102_single.
### The network includes the following layers:
1 'data' Image Input 224×224×3 images with 'zscore' normalization (SW Layer)
2 'conv1' Convolution 64 7×7×3 convolutions with stride [2 2] and padding [3 3 3 3] (HW Layer)
3 'bn_conv1' Batch Normalization Batch normalization with 64 channels (HW Layer)
4 'conv1_relu' ReLU ReLU (HW Layer)
5 'pool1' Max Pooling 3×3 max pooling with stride [2 2] and padding [1 1 1 1] (HW Layer)
6 'res2a_branch2a' Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
7 'bn2a_branch2a' Batch Normalization Batch normalization with 64 channels (HW Layer)
8 'res2a_branch2a_relu' ReLU ReLU (HW Layer)
9 'res2a_branch2b' Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
10 'bn2a_branch2b' Batch Normalization Batch normalization with 64 channels (HW Layer)
11 'res2a' Addition Element-wise addition of 2 inputs (HW Layer)
12 'res2a_relu' ReLU ReLU (HW Layer)
13 'res2b_branch2a' Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
14 'bn2b_branch2a' Batch Normalization Batch normalization with 64 channels (HW Layer)
15 'res2b_branch2a_relu' ReLU ReLU (HW Layer)
16 'res2b_branch2b' Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
17 'bn2b_branch2b' Batch Normalization Batch normalization with 64 channels (HW Layer)
18 'res2b' Addition Element-wise addition of 2 inputs (HW Layer)
19 'res2b_relu' ReLU ReLU (HW Layer)
20 'res3a_branch2a' Convolution 128 3×3×64 convolutions with stride [2 2] and padding [1 1 1 1] (HW Layer)
21 'bn3a_branch2a' Batch Normalization Batch normalization with 128 channels (HW Layer)
22 'res3a_branch2a_relu' ReLU ReLU (HW Layer)
23 'res3a_branch2b' Convolution 128 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
24 'bn3a_branch2b' Batch Normalization Batch normalization with 128 channels (HW Layer)
25 'res3a' Addition Element-wise addition of 2 inputs (HW Layer)
26 'res3a_relu' ReLU ReLU (HW Layer)
27 'res3a_branch1' Convolution 128 1×1×64 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
28 'bn3a_branch1' Batch Normalization Batch normalization with 128 channels (HW Layer)
29 'res3b_branch2a' Convolution 128 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
30 'bn3b_branch2a' Batch Normalization Batch normalization with 128 channels (HW Layer)
31 'res3b_branch2a_relu' ReLU ReLU (HW Layer)
32 'res3b_branch2b' Convolution 128 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
33 'bn3b_branch2b' Batch Normalization Batch normalization with 128 channels (HW Layer)
34 'res3b' Addition Element-wise addition of 2 inputs (HW Layer)
35 'res3b_relu' ReLU ReLU (HW Layer)
36 'res4a_branch2a' Convolution 256 3×3×128 convolutions with stride [2 2] and padding [1 1 1 1] (HW Layer)
37 'bn4a_branch2a' Batch Normalization Batch normalization with 256 channels (HW Layer)
38 'res4a_branch2a_relu' ReLU ReLU (HW Layer)
39 'res4a_branch2b' Convolution 256 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
40 'bn4a_branch2b' Batch Normalization Batch normalization with 256 channels (HW Layer)
41 'res4a' Addition Element-wise addition of 2 inputs (HW Layer)
42 'res4a_relu' ReLU ReLU (HW Layer)
43 'res4a_branch1' Convolution 256 1×1×128 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
44 'bn4a_branch1' Batch Normalization Batch normalization with 256 channels (HW Layer)
45 'res4b_branch2a' Convolution 256 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
46 'bn4b_branch2a' Batch Normalization Batch normalization with 256 channels (HW Layer)
47 'res4b_branch2a_relu' ReLU ReLU (HW Layer)
48 'res4b_branch2b' Convolution 256 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
49 'bn4b_branch2b' Batch Normalization Batch normalization with 256 channels (HW Layer)
50 'res4b' Addition Element-wise addition of 2 inputs (HW Layer)
51 'res4b_relu' ReLU ReLU (HW Layer)
52 'res5a_branch2a' Convolution 512 3×3×256 convolutions with stride [2 2] and padding [1 1 1 1] (HW Layer)
53 'bn5a_branch2a' Batch Normalization Batch normalization with 512 channels (HW Layer)
54 'res5a_branch2a_relu' ReLU ReLU (HW Layer)
55 'res5a_branch2b' Convolution 512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
56 'bn5a_branch2b' Batch Normalization Batch normalization with 512 channels (HW Layer)
57 'res5a' Addition Element-wise addition of 2 inputs (HW Layer)
58 'res5a_relu' ReLU ReLU (HW Layer)
59 'res5a_branch1' Convolution 512 1×1×256 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
60 'bn5a_branch1' Batch Normalization Batch normalization with 512 channels (HW Layer)
61 'res5b_branch2a' Convolution 512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
62 'bn5b_branch2a' Batch Normalization Batch normalization with 512 channels (HW Layer)
63 'res5b_branch2a_relu' ReLU ReLU (HW Layer)
64 'res5b_branch2b' Convolution 512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
65 'bn5b_branch2b' Batch Normalization Batch normalization with 512 channels (HW Layer)
66 'res5b' Addition Element-wise addition of 2 inputs (HW Layer)
67 'res5b_relu' ReLU ReLU (HW Layer)
68 'pool5' 2-D Global Average Pooling 2-D global average pooling (HW Layer)
69 'fc1000' Fully Connected 1000 fully connected layer (HW Layer)
70 'prob' Softmax softmax (HW Layer)
71 'ClassificationLayer_predictions' Classification Output crossentropyex with 'tench' and 999 other classes (SW Layer)
### Optimizing network: Fused 'nnet.cnn.layer.BatchNormalizationLayer' into 'nnet.cnn.layer.Convolution2DLayer'
### Notice: The layer 'data' of type 'ImageInputLayer' is split into 'data', 'data_norm_add', and 'data_norm'.
### Notice: The layer 'data' with type 'nnet.cnn.layer.ImageInputLayer' is implemented in software.
### Notice: The layer 'prob' with type 'nnet.cnn.layer.SoftmaxLayer' is implemented in software.
### Notice: The layer 'ClassificationLayer_predictions' with type 'nnet.cnn.layer.ClassificationOutputLayer' is implemented in software.
### Compiling layer group: conv1>>pool1 ...
### Compiling layer group: conv1>>pool1 ... complete.
### Compiling layer group: res2a_branch2a>>res2a_branch2b ...
### Compiling layer group: res2a_branch2a>>res2a_branch2b ... complete.
### Compiling layer group: res2b_branch2a>>res2b_branch2b ...
### Compiling layer group: res2b_branch2a>>res2b_branch2b ... complete.
### Compiling layer group: res3a_branch1 ...
### Compiling layer group: res3a_branch1 ... complete.
### Compiling layer group: res3a_branch2a>>res3a_branch2b ...
### Compiling layer group: res3a_branch2a>>res3a_branch2b ... complete.
### Compiling layer group: res3b_branch2a>>res3b_branch2b ...
### Compiling layer group: res3b_branch2a>>res3b_branch2b ... complete.
### Compiling layer group: res4a_branch1 ...
### Compiling layer group: res4a_branch1 ... complete.
### Compiling layer group: res4a_branch2a>>res4a_branch2b ...
### Compiling layer group: res4a_branch2a>>res4a_branch2b ... complete.
### Compiling layer group: res4b_branch2a>>res4b_branch2b ...
### Compiling layer group: res4b_branch2a>>res4b_branch2b ... complete.
### Compiling layer group: res5a_branch1 ...
### Compiling layer group: res5a_branch1 ... complete.
### Compiling layer group: res5a_branch2a>>res5a_branch2b ...
### Compiling layer group: res5a_branch2a>>res5a_branch2b ... complete.
### Compiling layer group: res5b_branch2a>>res5b_branch2b ...
### Compiling layer group: res5b_branch2a>>res5b_branch2b ... complete.
### Compiling layer group: pool5 ...
### Compiling layer group: pool5 ... complete.
### Compiling layer group: fc1000 ...
### Compiling layer group: fc1000 ... complete.
### Allocating external memory buffers:
offset_name offset_address allocated_space
_______________________ ______________ _________________
"InputDataOffset" "0x00000000" "24.0 MB"
"OutputResultOffset" "0x01800000" "4.0 MB"
"SchedulerDataOffset" "0x01c00000" "8.0 MB"
"SystemBufferOffset" "0x02400000" "28.0 MB"
"InstructionDataOffset" "0x04000000" "4.0 MB"
"ConvWeightDataOffset" "0x04400000" "52.0 MB"
"FCWeightDataOffset" "0x07800000" "4.0 MB"
"EndOffset" "0x07c00000" "Total: 124.0 MB"
### Network compilation complete.
The output displays the size of the compiled network which is 124 MB. The entire 124 MB is transferred to the FPGA by using the deploy method. Due to the large size of the network, the transfer can take a significant amount of time if using JTAG. When using Ethernet, the transfer happens quickly.
Deploy Deep Learning Network to FPGA
Before deploying a network, you must first establish a connection to the FPGA board. The dlhdl.Target object represents this connection between the host computer and the FPGA. Create two target objects, one for connection through the JTAG interface and one for connection through the Ethernet interface. To use the JTAG connection, install Xilinx™ Vivado™ Design Suite 2022.1 and set the path to your installed Xilinx Vivado executable if it is not already set up.
% hdlsetuptoolpath('ToolName', 'Xilinx Vivado', 'ToolPath', 'C:\Xilinx\Vivado\2022.1\bin\vivado.bat'); hTargetJTAG = dlhdl.Target('Xilinx', 'Interface', 'JTAG')
hTargetJTAG =
TargetJTAG with properties:
Interface: JTAG
Vendor: 'Xilinx'
hTargetEthernet = dlhdl.Target('Xilinx', 'Interface', 'Ethernet')
hTargetEthernet =
TargetEthernet with properties:
Interface: Ethernet
IPAddress: '192.168.1.101'
Username: 'root'
Port: 22
Vendor: 'Xilinx'
To deploy the network, assign the target object to the dlhdl.Workflow object and execute the deploy method. The deployment happens in two stages. First, the bitstream is programmed onto the FPGA. Then, the network is transferred to the onboard memory.
Select the JTAG interface and time the operation. This operation might take several minutes.
hW.Target = hTargetJTAG; tic; deploy(hW);
### Programming FPGA Bitstream using JTAG... ### Programming the FPGA bitstream has been completed successfully. ### Loading weights to Conv Processor. ### Conv Weights loaded. Current time is 13-Dec-2021 13:55:43 ### Loading weights to FC Processor. ### FC Weights loaded. Current time is 13-Dec-2021 13:55:51
elapsedTimeJTAG = toc
elapsedTimeJTAG = 419.3838
Use the Ethernet interface by setting the dlhdl.Workflow target object to hTargetEthernet and running the deploy function. There is a significant acceleration in the network deployment when you use Ethernet to deploy the bitstream and network to the FPGA.
hW.Target = hTargetEthernet; tic; deploy(hW);
### Programming FPGA Bitstream using Ethernet... Downloading target FPGA device configuration over Ethernet to SD card ... # Copied /tmp/hdlcoder_rd to /mnt/hdlcoder_rd # Copying Bitstream hdlcoder_system.bit to /mnt/hdlcoder_rd # Set Bitstream to hdlcoder_rd/hdlcoder_system.bit # Copying Devicetree devicetree_dlhdl.dtb to /mnt/hdlcoder_rd # Set Devicetree to hdlcoder_rd/devicetree_dlhdl.dtb # Set up boot for Reference Design: 'AXI-Stream DDR Memory Access : 3-AXIM' Downloading target FPGA device configuration over Ethernet to SD card done. The system will now reboot for persistent changes to take effect. System is rebooting . . . . . . ### Programming the FPGA bitstream has been completed successfully. ### Loading weights to Conv Processor. ### Conv Weights loaded. Current time is 13-Dec-2021 13:56:31 ### Loading weights to FC Processor. ### FC Weights loaded. Current time is 13-Dec-2021 13:56:31
elapsedTimeEthernet = toc
elapsedTimeEthernet = 39.4850
Changing from JTAG to Ethernet, the deploy function reprograms the bitstream, which accounts for most of the elapsed time. Reprogramming is due to different methods that are used to program the bitstream for the different hardware interfaces. The Ethernet interface configures the ARM processor and uses a persistent programming method so that the bitstream is reprogrammed each time the board is turned on. When deploying different deep learning networks by using the same bitstream and hardware interface, you can skip the bitstream programming, which further speeds up network deployment.
Run Prediction for Example Image
Run a prediction for an example image by using the predict method.
imgFile = 'monitor.jpg';
inputImg = imresize(imread(imgFile), [224,224]);
imshow(inputImg)
prediction = predict(hW,single(inputImg));
### Finished writing input activations. ### Running single input activation.
[val, idx] = max(prediction);
result = net.Layers(end).ClassNames{idx}result = 'monitor'
Release any hardware resources associated with the dlhdl.Target objects.
release(hTargetJTAG) release(hTargetEthernet)
See Also
dlhdl.Workflow | dlhdl.Target | activations | compile | deploy | predict
Related Topics
You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)
Asia Pacific
- Australia (English)
- India (English)
- New Zealand (English)
- 中国
- 日本Japanese (日本語)
- 한국Korean (한국어)