rankfeatures
Rank key features by class separability criteria
Syntax
Description
IDX = rankfeatures(X,GROUP)X using an independent evaluation criterion for
binary classification. X is a matrix where every column is an observed
vector and the number of rows corresponds to the original number of features.
GROUP contains the class labels. IDX is a list
of indices to the rows of X with the most significant features.
IDX = rankfeatures(X,GROUP,Name=Value)
Examples
Find a reduced set of genes that is sufficient for differentiating breast cancer cells from all other types of cancer in the t-matrix NCI60 data set.
Load sample data.
load NCI60tmatrixGet a logical index vector to the breast cancer cells.
BC = GROUP == 8;
Select features.
I = rankfeatures(X,BC,NumberOfIndices=12);
Test features with a linear discriminant classifier.
C = classify(X(I,:)',X(I,:)',double(BC)); cp = classperf(BC,C); cp.CorrectRate
ans = 1
Use cross-correlation weighting to further reduce the required number of genes.
I = rankfeatures(X,BC,'CCWeighting',0.7,'NumberOfIndices',8); C = classify(X(I,:)',X(I,:)',double(BC)); cp = classperf(BC,C); cp.CorrectRate
ans = 1
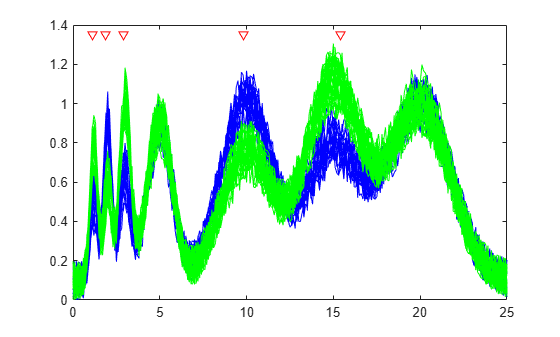
Find the discriminant peaks of two groups of signals with Gaussian pulses modulated by two different sources.
Load data.
load GaussianPulsesSpecify the regional information to outweigh Z-value of features as a function handle. Set the number of output indices to 5.
f = rankfeatures(y',grp,NWeighting=@(x) x/10+5,NumberOfIndices=5); plot(t,y(grp==1,:),'b',t,y(grp==2,:),'g',t(f),1.35,'vr');
Input Arguments
Name-Value Arguments
Output Arguments
References
[1] Theodoridis, Sergios, and Konstantinos Koutroumbas. Pattern Recognition. San Diego: Academic Press, 1999: 341-342.
[2] Liu, Huan, and Hiroshi Motoda. Feature Selection for Knowledge Discovery and Data Mining. Kluwer International Series in Engineering and Computer Science 454. Boston: Kluwer Academic Publishers, 1998.
[3] Ross, Douglas T., Uwe Scherf, Michael B. Eisen, Charles M. Perou, Christian Rees, Paul Spellman, Vishwanath Iyer, et al. “Systematic Variation in Gene Expression Patterns in Human Cancer Cell Lines.” Nature Genetics 24, no. 3 (March 2000): 227–35.
Version History
Introduced before R2006a
See Also
classperf | crossvalind | randfeatures | classify | sequentialfs