Integrate YOLO v2 Vehicle Detector System on SoC
This example shows how to simulate a you-only-look-once (YOLO) vehicle detector in Simulink® and verify the functionality of the application in MATLAB®. The end-to-end application includes preprocessing of input images, a YOLO v2 vehicle detection network, and postprocessing of the images to overlay detection results.
This YOLO v2 vehicle detection application has three main modules. The preprocessing module accepts the input frame and performs image resizing and normalization. The YOLO v2 vehicle detection network is a feature extraction network followed by a detection network. The combined network module consumes the preprocessed data and returns bounding boxes. The postprocessing module identifies the strongest bounding boxes and overlays the bounding boxes on the input images. The diagram shows the vehicle detection process.

The preprocessing subsystem and deep learning (DL) IP core are designed for deployment to an FPGA, which is also referred to as programmable logic (PL). The postprocessing subsystem is designed for deployment to an ARM™ processor, which is also referred to as processing system (PS). To deploy the vehicle detector, see YOLO v2 Vehicle Detector with Live Camera Input on Zynq-Based Hardware. This example shows how to model the preprocessing module, DL IP handshaking logic and network execution, and the postprocessing module.
Download Camera Data and Network
This example uses PandasetCameraData.mp4, that contains video from the Pandaset dataset, as the input video and either yolov2VehicleDetector32Layer.mat or yolov2VehicleDetector60Layer.mat as the DL network. Download the .zip file from Mathworks support website and unzip the downloaded file.
PandasetZipFile = matlab.internal.examples.downloadSupportFile('visionhdl','PandasetCameraData.zip'); [outputFolder,~,~] = fileparts(PandasetZipFile); unzip(PandasetZipFile,outputFolder); pandasetVideoFile = fullfile(outputFolder,'PandasetCameraData'); addpath(pandasetVideoFile);
Explore Vehicle Detector
The vehicle detector model contains these parts:
Source — Selects the input image from Pandaset.
Conversion — Converts the input frame into an RGB pixel stream.
Pixel Stream Preprocessing — Preprocesses the input frame and writes it to memory. This part of the algorithm is designed for deploying to the FPGA.
Deep Learning IP Core — Models the DL processor to calculate activations on the input frame and writes the output to memory.
Conversion — Converts the input RGB pixel stream to frames for overlaying bounding boxes.
Postprocessing and Overlay (to ARM) — Applies postprocessing to the network output and overlays the bounding boxes on each input frame.
Display — Displays the input frame with detection overlays.
open_system('YOLOv2VehicleDetectorOnSoC'); close_system('YOLOv2VehicleDetectorOnSoC/Video Viewer');
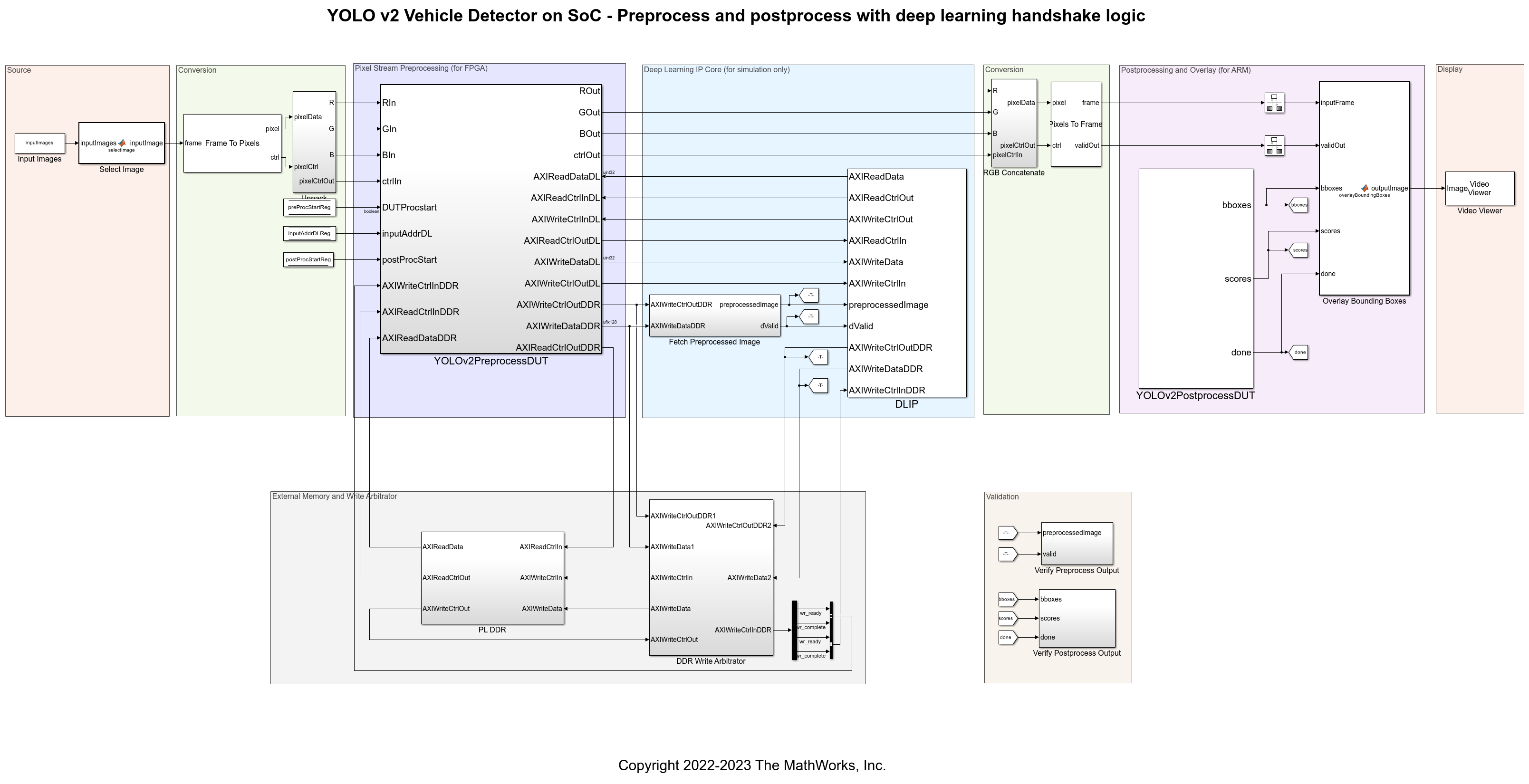
In this example, the inputImages variable stores numFrames number of images from Pandaset. The YOLOv2PreprocessDUT subsystem resizes and normalizes the input frames and then writes the preprocessed output to memory at the address location that it reads from the DL input handshaking registers (InputValid, InputAddr, InputSize). The DL IP subsystem calculates activations on the preprocessed image, writes the activations to memory, and updates the DL output handshaking registers (OutputValid, OutputAddr, OutputSize). This handshaking triggers the YOLOv2PostprocessDUT subsystem to read the DL output from the address information in the DL registers. Then, the subsystem postprocesses the video data to calculate and overlay bounding boxes. The VideoViewer block displays the results.
The example supports both floating-point and quantized workflows for simulation. In the quantized workflow, the YOLOv2PreprocessDUT subsystem converts the preprocessed output to int8 datatype before writing it to PL DDR. Similarly, YOLOv2PostprocessDUT subsystem converts the DL Output from int8 to single datatype before performing post processing.
The selectImage subsystem selects the input frame. A Frame To Pixels block converts the input image to a pixel stream and pixelcontrol bus. The Unpack subsystem divides the pixel stream into RGB components and feeds the RGB data (RIn, GIn, BIn) and a control bus to the preprocessor. The preprocessor also streams the image out as (ROut, GOut, BOut). This stream goes to the postprocessor for overlaying the bounding boxes.
Preprocessor
The YOLOv2PreprocessDUT subsystem contains subsystems that drop frames if the DL IP is not ready for input or select a region of interest (ROI) from the frame, preprocess (resize and normalize) the input frames, and interface with the DL IP.
open_system('YOLOv2VehicleDetectorOnSoC/YOLOv2PreprocessDUT');

The Frame Drop subsystem synchronizes data between the YOLOv2PreprocessDUT and DLIP subsystems by dropping the input frames if DLIP is not available for processing. It contains finite state machine (FSM) logic for reading DLIP registers and a Pixel Bus Creator block to concatenate the output control signals of the frame drop logic into a pixelcontrol bus. The readInputRegisters subsystem reads the inputAddrReg register, forwards the first frame to preprocessing, and resets the control signals for subsequent frames until the DLIP updates inputAddr. The DLIP subsystem processes one frame for each inputAddr.
The ROI Selector block selects an ROI from the 1920-by-1080 input image. This ROI is scaled down by a factor of 4 for faster simulation. The helperSLYOLOv2Setup function sets these variables that configure the ROI Selector block and the ROI input of the DUT.
hPos = 350; vPos = 400; hSize = 1000; vSize = 600;
The YOLO v2 Preprocess Algorithm subsystem contains subsystems that perform resizing and normalization. The Resize subsystem uses the Image Resizer block to resize the input image to the size expected by the deep learning network based on the inputSize and outputSize values provided to the DUT. The default value of inputSize is [600, 1000] and the default value of outputSize is [128, 128]
The Normalization subsystem rescales the pixels in the resized frame based on the inputMin and inputMax parameters so that all pixel values are in the range [0,1]. The inputMin and inputMax values are minimum and maximum pixel values of the first frame in the PandasetCameraData.mp4 video. The output of YOLO v2 Preprocess Algorithm is sent to Data Type Conversion subsystem for updating the precision of preprocess output to be written to DDR.
The Data Type Conversion subsystem converts the output of YOLO v2 Preprocess Algorithm that is in single datatype to either uint32 or int8 datatype. The resulting output is passed to the DL Handshake Logic Ext Mem subsystem to be written into the PL DDR.
The DL Handshake Logic Ext Mem subsystem contains finite state machine (FSM) logic for handshaking with DLIP and a subsystem to write the frame to memory. The Read DL Registers subsystem has the FSM logic to read the handshaking signals (InputValid, InputAddr, and InputSize) from DLIP for multiple frames. The Write to DDR subsystem uses these handshaking signals to write the preprocessed frame to the memory using AXI4 protocol. For more information on the Yolov2PreprocessDUT see, Deploy and Verify YOLO v2 Vehicle Detector on FPGA.
Deep Learning IP Core
The DLIP subsystem contains subsystems for prediction logic, DL input and output register handshaking logic, and an AXI4 Write controller to write the output to memory.
open_system('YOLOv2VehicleDetectorOnSoC/DLIP','force');

The FetchPreprocessedImage subsystem reads and rearranges the output from YOLOv2PreprocessDUT to the size required by the deep learning network (networkInputSize). The helperSLYOLOv2Setup and fetchActivations functions set up the network and the activation layer.
This example uses a YOLO v2 network that was pretrained on Pandaset data. The network concatenates the pixel elements in the third dimension to return output data in the external memory data format of the DL processor. For more information, see Deep Learning Processor IP Core External Memory Data Format (Deep Learning HDL Toolbox).
The AXIM Write Controller MATLAB Function block writes the DL output to memory. The DDR Write Arbitrator multiplexes write operations from the YOLOv2PreprocessDUT and DLIP subsystems.
Postprocessor
The YOLOv2PostprocessDUT subsystem contains subsystems for handshaking, reading network output, and transforming and postprocessing the network output.
open_system('YOLOv2VehicleDetectorOnSoC/YOLOv2PostprocessDUT','force');

The DL handshaking subsystems have variant behavior depending on whether you configure the model for simulation or deployment using the simulationFlag variable. This example demonstrates the simulation workflow, so the helperSLYOLOv2Setup function sets simulationFlag = true.
The Set Control Registers subsystem sets the control registers for YOLOv2PreprocessDUT, postProcStart, DUTProcStart, and inputAddrReg. The DL Handshaking subsystem reads the DL output handshaking registers (OutputValid, OutputAddr, OutputSize) that indicate address, size, and validity of the output. The model abstracts these registers as datastore blocks for simulation. The readDLOutput subsystem uses these handshaking signals and reads the DL output from the memory.
The readDLOutput subsystem contains subsystems for polling OutputValid, generating read requests, and reading DL output from memory. The pollOutputValid MATLAB Function block polls for the OutputValid signal from DLIP and triggers postprocessing when OutputValid is asserted. The rdDone signal inside the Read DL Output from PL DDR subsystem indicates that the DL output read operation is complete. The TriggerDLOutputNext subsystem pulses the OutputNext signal when rdDone is asserted to indicate to the DLIP that the output of current frame has been read.
The Data Type Conversion subsystem converts the datatype of the DL output from PL DDR using the DLOutputExponent which varies based on whether a floating point or quantized workflow is selected.
The yolov2TransformlayerandPostprocess MATLAB Function block transforms the DL output by reformatting the data, normalizing, and thresholding the bounding boxes with a confidence score of 0.4. The function returns the bounding boxes and pulses the postProcDone signal to indicate that the postprocessing is complete.
The helperSLYOLOv2Setup function sets these DL network parameters. The YOLOv2PostprocessDUT subsystem configures the network by using these values.
vehicleDetector = load(networkmatfile); detector = vehicleDetector.detector; net = detector.Network; anchorBoxes = detector.AnchorBoxes; networkInputSize = net.Layers(1,1).InputSize; networkOutputSize = [16,16,12]; paddedOutputSize = (networkOutputSize(1)*networkOutputSize(2)*networkOutputSize(3)*4)/3; inputImageROI = [hPos,vPos,hSize,vSize]; inputROISize = [vSize,hSize,numComponents]; confidenceThreshold = 0.4;
Quantized Deep Learning Workflow
To use the quantized workflow, you must have the Deep Learning Toolbox Model Quantization Library add-on installed.
The Data Type Conversion subsystem, part of YOLO v2 Preprocess Algorithm adds the single2int8 blocks when the quantized workflow is chosen. It uses the inputImageExponent value to convert data from single to int8 datatype. The floating point latency value Fixdt_0_16_0_To_SingleLatency, is used to set the latency values of floating point operators in single2int8 block as mentioned in the Latency Values of Floating-Point Operators (HDL Coder) page.
The YOLOv2PostprocessDUT block contains another Data Type Conversion subsystem which converts the DL Output from int8 to single datatype, using the DLOutputExponent value.
The helperSLYOLOv2Setup function calculates the values of inputImageExponent and DLOutputExponent based on the deep learning network you choose.
Simulate Vehicle Detector
Configure the network for the vehicle detector for simulation by using the helperSLYOLOv2Setup function. This function accepts three inputs, networkConfig, networkDataType, and mode.
helperSLYOLOv2Setup();
For
networkConfig, you can specify a 32-layer network (default,"32Layer") or a 60-layer network ("60Layer").networkDataTypedetermines the precision of the vehicle detector. Specify"single"to run the vehicle detector with floating-point (single) precision. Specify"8bitScaled"to run the vehicle detector with the quantized workflow. The default value ofnetworkDataTypeis"single".Set the value of
modeto"simulation"to configure the model for simulation.
helperSLYOLOv2Setup("32Layer", "single", "simulation");
When you compile the model for the first time, the diagram takes a few minutes to update. Update the model before running the simulation.
set_param("YOLOv2VehicleDetectorOnSoC", SimulationCommand="update"); out = sim("YOLOv2VehicleDetectorOnSoC");
### Searching for referenced models in model 'YOLOv2VehicleDetectorOnSoC'. ### Total of 2 models to build. ### Starting serial model build. ### Successfully updated the model reference simulation target for: DLHandshakeLogicExtMem ### Successfully updated the model reference simulation target for: YOLOv2PreprocessAlgorithm Build Summary Model reference simulation targets: Model Build Reason Status Build Duration ============================================================================================================================ DLHandshakeLogicExtMem Information cache folder or artifacts were missing. Code generated and compiled. 0h 1m 6.1016s YOLOv2PreprocessAlgorithm Information cache folder or artifacts were missing. Code generated and compiled. 0h 2m 38.346s 2 of 2 models built (0 models already up to date) Build duration: 0h 3m 49.611s

Verify YOLOv2PreprocessDUT and YOLOv2PostprocessDUT Using MATLAB
The example model includes subsystems for verifying the outputs of YOLOv2PreprocessDUT and YOLOv2PostprocessDUT. The Verify Preprocess Output and Verify Postprocess Output subsystems log the signals that you need to verify the preprocessed image and bounding boxes, respectively. Run the helper function to display the results.
helperVerifyVehicleDetector;


The helperVerifyVehicleDetector script verifies the preprocessed images from simulation against the reference image obtained by applying resize and normalize operations. It also compares the bounding boxes from simulation with those from the calling the detect (Computer Vision Toolbox) function on the input images.