Classify Human Voice Using YAMNet on Android Device
This example shows how to use the Simulink® Support Package for Android® Devices and a pretrained YAMNet network to classify human voices.
Prerequisites
For more information on how to use the Simulink Support Package for Android Devices to run a Simulink model on your Android device, see Getting Started with Android Devices.
Download and install ARM® Compute Library using the Hardware Setup screen. This example uses ARM Compute Library version 20.02.1. To configure the ARM Compute Library in the Simulink model, see the section Configure ARM Compute Library Parameters in this example. For more information on the Hardware Setup screen, see Install Support for Android Devices.
Required Hardware
Android device such as a phone or tablet
USB cable
Hardware Setup
Connect your Android device to the host computer using the USB cable.
Download and Unzip Audio Toolbox Support for YAMNet
In MATLAB® Command Window, execute these commands to download and unzip the YAMNet model to your temporary directory.
downloadFolder = fullfile(tempdir,'YAMNetDownload'); loc = websave(downloadFolder,'https://ssd.mathworks.com/supportfiles/audio/yamnet.zip'); YAMNetLocation = tempdir; unzip(loc,YAMNetLocation) addpath(fullfile(YAMNetLocation,'yamnet'))
Observe the Workspace pane in MATLAB.

Get Human Sounds in AudioSet Ontology
Select only human sounds in the AudioSet ontology. Use the yamnetGraph (Audio Toolbox) function to obtain a graph of the AudioSet ontology and a list of all sounds supported by YAMNet. The dfsearch function returns a vector of 'Music' sounds in the order of their discovery using depth-first search.
[ygraph, allSounds] = yamnetGraph; humanVoice = dfsearch(ygraph,"Human voice");
Find the location of these musical sounds in the list of supported sounds.
[~,HumanVoiceIndices] = intersect(allSounds,humanVoice)
HumanVoiceIndices = 5 21 15 8 18 28 30 2 11 26 . . .
Observe humanVoice and HumanVoiceIndices in the Workspace.
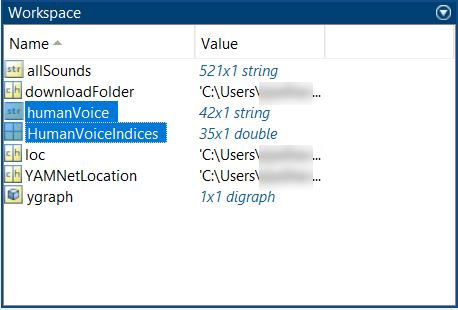
Double-click the humanVoice string from the Workspace or execute this command to view the voices classified under human voices.
humanVoice
humanVoice =
42x1 string array
"Human voice" "Speech" "Male speech, man speaking" "Female speech, woman speaking" "Child speech, kid speaking" "Conversation" "Narration, monologue" "Babbling" "Speech synthesizer" "Shout" . . .
Configure Simulink Model and Calibrate Parameters
Open the androidClassifyHumanVoice Simulink model.
Configure ARM Compute Library Version in Simulink Model
In the Modeling tab of the Simulink model, in the Setup section, click Model Settings.
In the Configuration Parameters dialog box, in the left pane, go to Code Generation > Interface.
In the Deep learning section, set ARM Compute Library version to the version you already set in the Hardware Setup screen. In this example, it is set to
20.02.1.
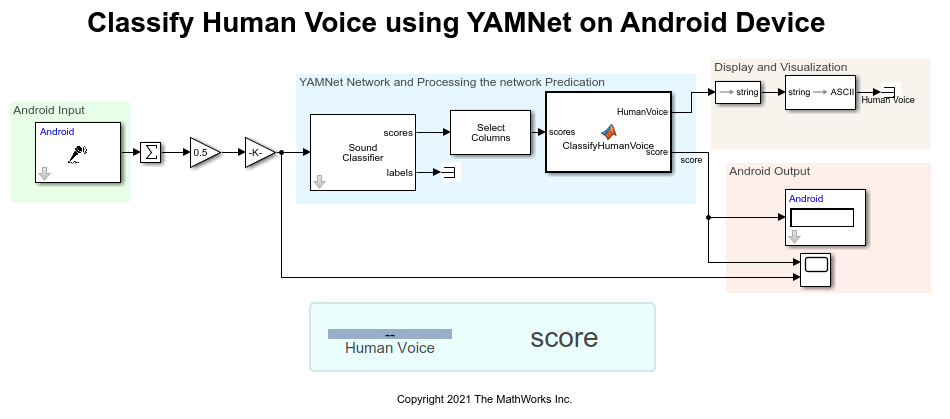
androidClassifyHumanVoice Simulink Model
The output from the Audio Capture block is converted from stereo to mono and then provided to the Sound Classifier block. The sampling frequency and frame size of the audio signal output is 44100 Hz and 4410 Hz, respectively. The YAMNet network requires you to preprocess and extract features from audio signals by converting them to the sample rate the network was trained on (44100 Hz), and then extracting overlapping mel spectrograms. The Sound Classifier block does the required preprocessing and feature extraction that is necessary to match the preprocessing and feature extraction used to train YAMNet. This block detects the scores and labels of the input audio.
Configure these parameters in the Block Parameters dialog box of the Sound Classifier (Audio Toolbox) block.
Set Sample rate of input signal (Hz) to
44100.Set Overlap percentage (%) to
50.Set Outputs to
Predictions.
The Selector in the model picks the scores related to human voices using the vector of indices given by HumanVoiceIndices. In the ClassifyHumanVoice function in the MATLAB Function block, if the maximum value of the scores is greater than 0.2, then the score is related to human voices.
Configure ARM Compute Library Parameters
Select a version of ARM Compute Library from the Configuration Parameters dialog box.
1. On the Hardware tab of the androidClassifyHumanVoice Simulink model, select Configuration Parameters > Code Generation. In the Target selection section, set Language to C++.
2 Select Code Generation > Interface. In the Deep Learning section, set these parameters.
a. Set Target library to ARM Compute.
b. Set ARM Compute Library version to 20.02.1. This example supports the latest version of ARM Compute Library.
c. Set ARM Compute Library architecture to armv7.
3. Click Apply > OK.
Deploy Simulink Model on Android Device
On the Hardware tab of the Simulink model, in the Mode section, click Run on board. In the Deploy section, click Build, Deploy & Start. The androidClassifyHumanVoice application launches automatically. Speak through the microphone and observe the Dashboard tab of the application. In the Panel section, the type of human voice classified by the YAMNet network is displayed with its probability in the Score section.

The App tab of the application displays the maximum score value of the predicted class.

Similarly, observe the score for different classes of human voices.
Other Things to Try
Google® provides a website where you can explore the AudioSet ontology and the corresponding data set: https://research.google.com/audioset/ontology/index.html. Explore this data set and classify a wide range of sounds.