Create and Train Custom LQR Agent
This example shows how to create and train a custom linear quadratic regulation (LQR) agent to control a discrete-time linear system modeled in MATLAB®. For a introduction to custom agents, see Create Custom Reinforcement Learning Agents. For a step by step example on how to create a custom PG agent (using the REINFORCE algorithm) see Create and Train Custom PG Agent. For an example of how a DDPG agent can be used as an optimal controller for a discrete-time system, see Compare DDPG Agent to LQR Controller.
Create Linear System Environment
The reinforcement learning environment for this example is a discrete-time linear system. The dynamics for the system are given by
The feedback control law is
The control objective is to minimize the quadratic cost: .
In this example, the system matrices are
A = [1.05,0.05,0.05;0.05,1.05,0.05;0,0.05,1.05]; B = [0.1,0,0.2;0.1,0.5,0;0,0,0.5];
The quadratic cost matrices are:
Q = [10,3,1;3,5,4;1,4,9]; R = 0.5*eye(3);
For this environment, the reward at time is given by , which is the negative of the quadratic cost. Therefore, maximizing the reward minimizes the cost. The initial conditions are set randomly by the reset function.
Create the MATLAB environment interface for this linear system and reward. The myDiscreteEnv function creates an environment by defining custom step and reset functions. For more information on creating such a custom environment, see Create Custom Environment Using Step and Reset Functions.
env = myDiscreteEnv(A,B,Q,R);
Fix the random generator seed for reproducibility.
rng(0)
Create Custom LQR Agent
For the LQR problem, the Q-value function for a given control gain is quadratic and can be defined as , where is a symmetric, positive definite matrix.
The control law that maximizes is , so the feedback gain is .
The matrix contains distinct element values, where is the sum of the number of states and number of inputs. Denote as the vector containing these elements, in which the off-diagonal elements in are multiplied by two. The elements of are the parameters that the custom agent needs to learn.
You can express the Q-value function as the inner product of the vectors and : , where is a vector of quadratic monomials built from the combination of all the elements in and . For an example, see the matrix in Compare DDPG Agent to LQR Controller.
The LQR agent starts with a stabilizing controller . To get an initial stabilizing controller, place the poles of the closed-loop system inside the unit circle.
K0 = place(A,B,[0.4,0.8,0.5]);
To create a custom agent, you must create a subclass of the rl.agent.CustomAgent abstract class. For the custom LQR agent, the defined custom subclass is LQRCustomAgent. For more information, see Create Custom Reinforcement Learning Agents. Create the custom LQR agent using , , and . The agent does not require information on the system matrices and .
agent = LQRCustomAgent(Q,R,K0);
For this example, set the agent discount factor to one. To use a discounted future reward, set the discount factor to a value less than one.
agent.Gamma = 1;
Because the linear system has three states and three inputs, the total number of learnable parameters is . To ensure satisfactory performance of the agent, set the number of parameter estimates (the number of data point to be collected before updating the critic) to be greater than twice the number of learnable parameters. In this example, the value is .
agent.EstimateNum = 45;
To get good estimation results for , you must apply a persistently excited exploration model to the system. In this example, encourage model exploration by adding white noise to the controller output: . In general, the exploration model depends on the system models.
Train Agent
To train the agent, first specify the training options. For this example, use the following options.
Run each training episode for at most 10 episodes, with each episode lasting at most 50 time steps.
Display the training progress in the Reinforcement Learning Training Monitor dialog box (set the
Plotsoption) and disable command line display (set theVerboseoption).
For more information, see rlTrainingOptions.
trainingOpts = rlTrainingOptions(... MaxEpisodes=10, ... MaxStepsPerEpisode=50, ... Verbose=false, ... Plots="training-progress");
Train the agent using the train function.
trainingStats = train(agent,env,trainingOpts);
Simulate Agent and Compare with Optimal Solution
To validate the performance of the trained agent, simulate it within the MATLAB environment. For more information on agent simulation, see rlSimulationOptions and sim.
simOptions = rlSimulationOptions(MaxSteps=20); experience = sim(env,agent,simOptions); totalReward = sum(experience.Reward)
totalReward = -30.6482
You can compute the optimal solution for the LQR problem using the dlqr function.
[Koptimal,P] = dlqr(A,B,Q,R);
The optimal reward is given by .
x0 = experience.Observation.obs1.getdatasamples(1); Joptimal = -x0'*P*x0;
Compute the error in the reward between the trained LQR agent and the optimal LQR solution.
rewardError = totalReward - Joptimal
rewardError = 5.0439e-07
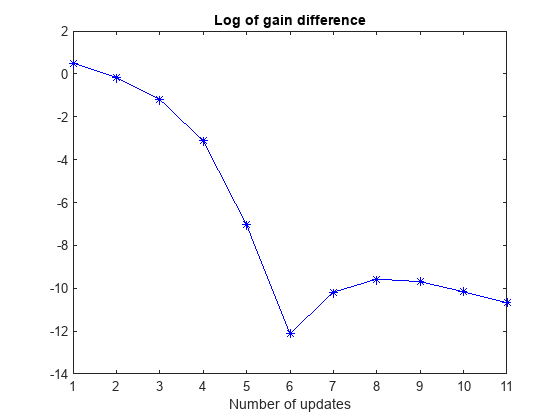
View the history of the norm of the difference between the gains between the trained LQR agent and the optimal LQR solution.
% Number of gain updates len = agent.KUpdate; % Initialize error vector err = zeros(len,1); % Fill elements for i = 1:len err(i) = norm(agent.KBuffer{i}-Koptimal); end % Plot logarithm of the error vector plot(log10(err),'b*-') title("Log of gain difference") xlabel("Number of updates")
Compute the norm of final error for the feedback gain.
gainError = norm(agent.K - Koptimal)
gainError = 2.1203e-11
Overall, the trained agent finds a solution that is very close to the true optimal LQR solution.
See Also
Functions
Objects
Related Examples
- Create and Train Custom PG Agent
- Compare DDPG Agent to LQR Controller
- Create Custom Environment Using Step and Reset Functions
- Train Reinforcement Learning Policy Using Custom Training Loop
More About
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)