Get Started with Image Preprocessing and Augmentation for Deep Learning
Data preprocessing consists of a series of deterministic operations that normalize or enhance desired data features. For example, you can normalize data to a fixed range or rescale data to the size required by the network input layer. Preprocessing is used for training, validation, and inference.
Preprocessing can occur at two stages in the deep learning workflow.
Commonly, preprocessing occurs as a separate step that you complete before preparing the data to be fed to the network. You load your original data, apply the preprocessing operations, then save the result to disk. The advantage of this approach is that the preprocessing overhead is only required once, then the preprocessed images are readily available as a starting place for all future trials of training a network.
If you load your data into a datastore, then you can also apply preprocessing during training by using the
transformandcombinefunctions. For more information, see Datastores for Deep Learning (Deep Learning Toolbox). The transformed images are not stored in memory. This approach is convenient to avoid writing a second copy of training data to disk if your preprocessing operations are not computationally expensive and do not noticeably impact the speed of training the network.
Data augmentation consists of randomized operations that are applied to the training data while the network is training. Augmentation increases the effective amount of training data and helps to make the network invariant to common distortion in the data. For example, you can add artificial noise to training data so that the network is invariant to noise.
To augment training data, start by loading your data into a datastore. Some built-in
datastores apply a specific and limited set of augmentation to data for specific
applications. You can also apply your own set of augmentation operations on data in the
datastore by using the transform and
combine
functions. During training, the datastore randomly perturbs the training data for each
epoch, so that each epoch uses a slightly different data set. For more information, see
Preprocess Images for Deep Learning and Preprocess Volumes for Deep Learning.
Preprocess and Augment Images
Common image preprocessing operations include noise removal, edge-preserving smoothing, color space conversion, contrast enhancement, and morphology.
Augment image data to simulate variations in the image acquisition. For example, the most common type of image augmentation operations are geometric transformations such as rotation and translation, which simulate variations in the camera orientation with respect to the scene. Color jitter simulates variations of lighting conditions and color in the scene. Artificial noise simulates distortions caused by the electrical fluctuations in the sensor and analog-to-digital conversion errors. Blur simulates an out-of-focus lens or movement of the camera with respect to the scene.
You can process and augment image data using the operations in this table, as well as any other functionality in the toolbox. For an example that shows how to create and apply these transformations, see Augment Images for Deep Learning.
| Processing Type | Description | Sample Functions | Sample Output |
|---|---|---|---|
| Resize images | Resize images by a fixed scaling factor or to a target size |
| |
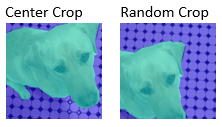
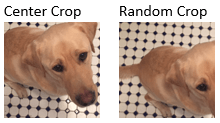
| Crop images | Crop an image to a target size from the center or a random position |
| |
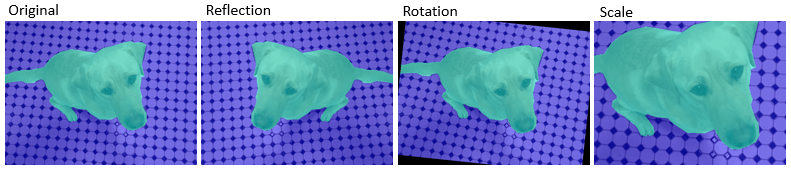
| Warp images | Apply random reflection, rotation, scale, shear, and translation to images |
| |
| Jitter color | Randomly adjust image hue, saturation, brightness, or contrast of color images |
| |
| Simulate noise | Add random Gaussian, Poisson, salt and pepper, or multiplicative noise |
| |
| Simulate blur | Add Gaussian or directional motion blur |
| |
| Jitter intensity | Randomly adjust the brightness, contrast, or gamma correction of grayscale images and volumes |
|
|






Preprocess and Augment Pixel Label Images for Semantic Segmentation
Semantic segmentation data consists of images and corresponding pixel labels represented as categorical arrays. For more information, see Get Started with Semantic Segmentation Using Deep Learning (Computer Vision Toolbox).
If you have Computer Vision Toolbox™, then you can use the Image Labeler (Computer Vision Toolbox) and the Video Labeler (Computer Vision Toolbox) apps to interactively label pixels and export the label data for training a neural network.
When you transform an image for semantic segmentation, you must perform an identical transformation to the corresponding pixel labeled image. You can preprocess pixel label images using the functions in the table and any other function that supports categorical input. For an example that shows how to create and apply these transformations, see Augment Pixel Labels for Semantic Segmentation (Computer Vision Toolbox).
| Processing Type | Description | Sample Functions | Sample Output |
|---|---|---|---|
| Resize pixel labels | Resize pixel label images by a fixed scaling factor or to a target size |
| |
| Crop pixel labels | Crop a pixel label image to a target size from the center or a random position |
| |
| Warp pixel labels | Apply random reflection, rotation, scale, shear, and translation to pixel label images |
|