Single-Rate Resource Sharing Architecture
This example shows how HDL Coder™ generates a single-rate architecture from a model to manage the execution of operations in the context of clock-rate pipelining and resource sharing. When you apply resource sharing to blocks in your design, HDL Coder decides the architecture to use based on the sample rate of the regions where sharing occurs. If resource sharing occurs in a region of the design that operates at the fastest base sample rate, then HDL Coder synthesizes a local multi-rate architecture, as described in Resource Sharing for Area Optimization. In this example, the shared resources are in a region that operates at a slower sample rate, so HDL Coder applies clock-rate pipelining and synthesizes a single-rate architecture.
Clock-rate pipelining is an optimization that finds separate regions of logic in a design that operate on data at a slower sample rate and inserts pipelining and resource sharing logic at the faster clock rate. In these cases, resource sharing is implemented as a time-multiplexed architecture that operates at a single rate and incurs a latency. In order to execute dependent operations and manage the additional latency, HDL Coder synthesizes appropriate scheduling logic.
Inspect Model
Open and update the model hdlcoder_singlerate_sharing.
load_system('hdlcoder_singlerate_sharing'); open_system('hdlcoder_singlerate_sharing/Subsystem'); set_param('hdlcoder_singlerate_sharing', 'SimulationCommand', 'update');

This model has an oversampling constraint defined by the Oversampling factor parameter, which specifies how much faster the FPGA clock rate runs with respect to the Simulink base sample time. This model sets the oversampling factor to 30 by using the command-line to set the property Oversampling, which means that the clock-rate pipelined region can consume 30 clock cycles to complete execution.
Generate HDL Code and Inspect Validation Model
List the optimization options for individual blocks and subsystems by using the function hdlsaveparams. Generate code and a validation model to see single-rate sharing architecture.
hdlsaveparams('hdlcoder_singlerate_sharing/Subsystem'); makehdl('hdlcoder_singlerate_sharing/Subsystem');
%% Set Model 'hdlcoder_singlerate_sharing' HDL parameters
hdlset_param('hdlcoder_singlerate_sharing', 'GenerateValidationModel', 'on');
hdlset_param('hdlcoder_singlerate_sharing', 'HDLSubsystem', 'hdlcoder_singlerate_sharing');
hdlset_param('hdlcoder_singlerate_sharing', 'Oversampling', 30);
% Set SubSystem HDL parameters
hdlset_param('hdlcoder_singlerate_sharing/Subsystem', 'DistributedPipelining', 'on');
hdlset_param('hdlcoder_singlerate_sharing/Subsystem/Sum_piped', 'Architecture', 'Tree');
% Set Sum HDL parameters
hdlset_param('hdlcoder_singlerate_sharing/Subsystem/Sum_piped', 'OutputPipeline', 2);
% Set SubSystem HDL parameters
hdlset_param('hdlcoder_singlerate_sharing/Subsystem/share', 'SharingFactor', 2);
% Set SubSystem HDL parameters
hdlset_param('hdlcoder_singlerate_sharing/Subsystem/stream1', 'StreamingFactor', 2);
% Set Delay HDL parameters
hdlset_param('hdlcoder_singlerate_sharing/Subsystem/stream1/Delay', 'UseRAM', 'on');
% Set SubSystem HDL parameters
hdlset_param('hdlcoder_singlerate_sharing/Subsystem/stream2', 'StreamingFactor', 4);
### Begin compilation of the model 'hdlcoder_singlerate_sharing'...
### Working on the model <a href="matlab:open_system('hdlcoder_singlerate_sharing')">hdlcoder_singlerate_sharing</a>
### Generating HDL for <a href="matlab:open_system('hdlcoder_singlerate_sharing/Subsystem')">hdlcoder_singlerate_sharing/Subsystem</a>
### Using the config set for model <a href="matlab:configset.showParameterGroup('hdlcoder_singlerate_sharing', { 'HDL Code Generation' } )">hdlcoder_singlerate_sharing</a> for HDL code generation parameters.
### Running HDL checks on the model 'hdlcoder_singlerate_sharing'.
### Begin compilation of the model 'hdlcoder_singlerate_sharing'...
### Working on the model 'hdlcoder_singlerate_sharing'...
### The DUT requires an initial pipeline setup latency. Each output port experiences these additional delays.
### Output port 1: 1 cycles.
### Working on... <a href="matlab:configset.internal.open('hdlcoder_singlerate_sharing', 'GenerateModel')">GenerateModel</a>
### Begin model generation 'gm_hdlcoder_singlerate_sharing'...
### Rendering DUT with optimization related changes (IO, Area, Pipelining)...
### Model generation complete.
### Generated model saved at <a href="matlab:open_system('hdlsrc/hdlcoder_singlerate_sharing/gm_hdlcoder_singlerate_sharing.slx')">hdlsrc/hdlcoder_singlerate_sharing/gm_hdlcoder_singlerate_sharing.slx</a>
### To highlight blocks that obstruct distributed pipelining, click the following MATLAB script: <a href="matlab:run('hdlsrc/hdlcoder_singlerate_sharing/highlightDistributedPipeliningBarriers')">hdlsrc/hdlcoder_singlerate_sharing/highlightDistributedPipeliningBarriers.m</a>
### To clear highlighting, click the following MATLAB script: <a href="matlab:run('hdlsrc/hdlcoder_singlerate_sharing/clearhighlighting.m')">hdlsrc/hdlcoder_singlerate_sharing/clearhighlighting.m</a>
### Generating new validation model: '<a href="matlab:open_system('hdlsrc/hdlcoder_singlerate_sharing/gm_hdlcoder_singlerate_sharing_vnl')">gm_hdlcoder_singlerate_sharing_vnl</a>'.
### Validation model generation complete.
### Begin VHDL Code Generation for 'hdlcoder_singlerate_sharing'.
### MESSAGE: The design requires 30 times faster clock with respect to the base rate = 0.1.
### Begin VHDL Code Generation for 'Subsystem_tc'.
### Working on Subsystem_tc as hdlsrc/hdlcoder_singlerate_sharing/Subsystem_tc.vhd.
### Code Generation for 'Subsystem_tc' completed.
### Working on hdlcoder_singlerate_sharing/Subsystem/share as hdlsrc/hdlcoder_singlerate_sharing/share.vhd.
### Working on hdlcoder_singlerate_sharing/Subsystem/stream1 as hdlsrc/hdlcoder_singlerate_sharing/stream1.vhd.
### Working on hdlcoder_singlerate_sharing/Subsystem/stream2 as hdlsrc/hdlcoder_singlerate_sharing/stream2.vhd.
### Working on crp_temp_MAC as hdlsrc/hdlcoder_singlerate_sharing/crp_temp_MAC.vhd.
### Working on hdlcoder_singlerate_sharing/Subsystem as hdlsrc/hdlcoder_singlerate_sharing/Subsystem.vhd.
### Generating package file hdlsrc/hdlcoder_singlerate_sharing/Subsystem_pkg.vhd.
### Code Generation for 'hdlcoder_singlerate_sharing' completed.
### Generating HTML files for code generation report at <a href="matlab:hdlcoder.report.openReportV2Dialog('/tmp/Bdoc26a_3233028_1589302/tpcb19e012/hdlcoder-ex08973016/hdlsrc/hdlcoder_singlerate_sharing', '/tmp/Bdoc26a_3233028_1589302/tpcb19e012/hdlcoder-ex08973016/hdlsrc/hdlcoder_singlerate_sharing/html/index.html')">index.html</a>
### Creating HDL Code Generation Check Report file:///tmp/Bdoc26a_3233028_1589302/tpcb19e012/hdlcoder-ex08973016/hdlsrc/hdlcoder_singlerate_sharing/Subsystem_report.html
### HDL check for 'hdlcoder_singlerate_sharing' complete with 0 errors, 3 warnings, and 4 messages.
### HDL code generation complete.
At the global level in the generated validation model, HDL Coder schedules each of these locally shared and streamed subsystems according to their latency. The unit of scheduling is a clock-rate pipelined region that has been automatically identified by HDL Coder. For each region, a Counter Limited block is used as a sequencer for the scheduling logic. In order to avoid generating identical counters, HDL Coder generates one global scheduling counter per model for all clock-rate pipelining regions that require the same size counter. The counter counts from zero to 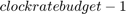 , where the budget is the ratio of the shared resource sample rate to the FPGA clock rate.
, where the budget is the ratio of the shared resource sample rate to the FPGA clock rate.
In this example, the budget is 30 because the Oversampling property is 30. HDL Coder assigns a time interval that each streamed and shared subsystem executes within. The subsystem is encapsulated in an enabled subsystem so that it is only active during that time interval. The counter or sequencer value specifies the current time step, and the logic that computes the time interval drives the enable inputs to these subsystems.
For each subsystem in the validation model that specifies resource sharing or streaming, a single-rate resource-shared architecture implements the time-division multiplexing. For example, see the validation model subsystem gm_hdlcoder_singlerate_sharing_vnl/Subsystem/share. If SharingFactor = N, it takes N-1 cycles to execute the shared architecture per cycle of the original computation.
Open the validation model subsystem gm_hdlcoder_singlerate_sharing_vnl/Subsystem/share.
open_system('gm_hdlcoder_singlerate_sharing_vnl/Subsystem/share'); set_param('gm_hdlcoder_singlerate_sharing_vnl', 'SimulationCommand', 'update');

The subsystem gm_hdlcoder_singlerate_sharing_vnl/Subsystem/share is assigned the time interval [2, 3] because the Sum of Elements block, hdlcoder_singlerate_sharing/Subsystem/Sum_piped has the HDL block property OutputPipeline set to 2 and is on the path between the DUT inputs and the inputs to this subsystem. The shared subsystem starts execution in time step two, and because the resource sharing property SharingFactor is set to 3, takes 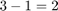 cycles to complete. The enable input to
cycles to complete. The enable input to gm_hdlcoder_singlerate_sharing_vnl/Subsystem/share/crp_temp_shared is asserted only when the global counter is greater than or equal to two and less than or equal to three.
In addition to streamed and shared subsystems, HDL Coder also schedules any blocks or subsystems that contain state or implement multi-cycle operations. For example, the design uses Multiply-Accumulate block in the gm_hdlcoder_singlerate_sharing_vnl/Subsystem/crp_temp_MAC subsystem that computes the dot-product on two four-element vectors. This logic takes four cycles to execute and is scheduled in the time interval [4, 7] because there are two streaming regions on the path from the inputs to the Multiply-Accumulate block. The first streaming region, gm_hdlcoder_singlerate_sharing_vnl/Subsystem/stream1, is scheduled in time interval [0, 1] due to a streaming factor of two. The second streaming region, gm_hdlcoder_singlerate_sharing_vnl/Subsystem/stream2, is scheduled in time interval [1, 4] due to a streaming factor of four.
The generated validation model has non-trivial changes from the original model, but models the single-rate sharing architecture that HDL Coder synthesizes and generates for the HDL code. This model also compares the numerics of the synthesized architecture with the original model except for differences accounted for by added latency. For more details, see Delay Balancing and Validation Model Workflow in HDL Coder. Run the validation model to compare the numerics between the generated and the original model in each time step. The model throws an error on mismatches.