Bisection Algorithm to Calculate Square Root of an Unsigned Fixed-Point Number
This example shows how to generate HDL code from MATLAB® design implementing a bisection algorithm to calculate the square root of a number in fixed point notation.
Same implementation, originally using n-multipliers in HDL code, for wordlength n, under sharing and streaming optimizations, can generate HDL code with only one multiplier demonstrating the power of MATLAB HDL Coder™ optimizations.
The design of the square-root algorithm shows the pipelining concepts to achieve a fast clock rate in resulting RTL design. Since this design is already in fixed point, you don't need to run fixed-point conversion.
MATLAB Design
% Design Sqrt design_name = 'mlhdlc_sqrt'; % Test Bench for Sqrt testbench_name = 'mlhdlc_sqrt_tb';
Lets look at the Sqrt Design
dbtype(design_name)
1 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
2 % MATLAB design: Pipelined Bisection Square root algorithm
3 %
4 % Introduction:
5 %
6 % Implement SQRT by the bisection algorithm in a pipeline, for unsigned fixed
7 % point numbers (also why you don't need to run fixed-point conversion for this design).
8 % The demo illustrates the usage of a pipelined implementation for numerical algorithms.
9 %
10 % Key Design pattern covered in this example:
11 % (1) State of the bisection algorithm is maintained with persistent variables
12 % (2) Stages of the bisection algorithm are implemented in a pipeline
13 % (3) Code is written in a parameterized fashion, i.e. word-length independent, to work for any size fi-type
14 %
15 % Ref. 1. R. W. Hamming, "Numerical Methods for Scientists and Engineers," 2nd, Ed, pp 67-69. ISBN-13: 978-0486652412.
16 % 2. Bisection method, http://en.wikipedia.org/wiki/Bisection_method, (accessed 02/18/13).
17 %
18
19 % Copyright 2013-2015 The MathWorks, Inc.
20
21 %#codegen
22 function [y,z] = mlhdlc_sqrt( x )
23 persistent sqrt_pipe
24 persistent in_pipe
25 if isempty(sqrt_pipe)
26 sqrt_pipe = fi(zeros(1,x.WordLength),numerictype(x));
27 in_pipe = fi(zeros(1,x.WordLength),numerictype(x));
28 end
29
30 % Extract the outputs from pipeline
31 y = sqrt_pipe(x.WordLength);
32 z = in_pipe(x.WordLength);
33
34 % for analysis purposes you can calculate the error between the fixed-point bisection routine and the floating point result.
35 %Q = [double(y).^2, double(z)];
36 %[Q, diff(Q)]
37
38 % work the pipeline
39 for itr = x.WordLength-1:-1:1
40 % move pipeline forward
41 in_pipe(itr+1) = in_pipe(itr);
42 % guess the bits of the square-root solution from MSB to the LSB of word length
43 sqrt_pipe(itr+1) = guess_and_update( sqrt_pipe(itr), in_pipe(itr+1), itr );
44 end
45
46 %% Prime the pipeline
47 % with new input and the guess
48 in_pipe(1) = x;
49 sqrt_pipe(1) = guess_and_update( fi(0,numerictype(x)), x, 1 );
50
51 %% optionally print state of the pipeline
52 %disp('************** State of Pipeline **********************')
53 %double([in_pipe; sqrt_pipe])
54
55 return
56 end
57
58 % Guess the bits of the square-root solution from MSB to the LSB in
59 % a binary search-fashion.
60 function update = guess_and_update( prev_guess, x, stage )
61 % Key step of the bisection algorithm is to set the bits
62 guess = bitset( prev_guess, x.WordLength - stage + 1);
63 % compare if the set bit is a candidate solution to retain or clear it
64 if ( guess*guess <= x )
65 update = guess;
66 else
67 update = prev_guess;
68 end
69 return
70 end
Simulate the Design
It is always a good practice to simulate the design with the testbench prior to code generation to make sure there are no runtime errors.
mlhdlc_sqrt_tb
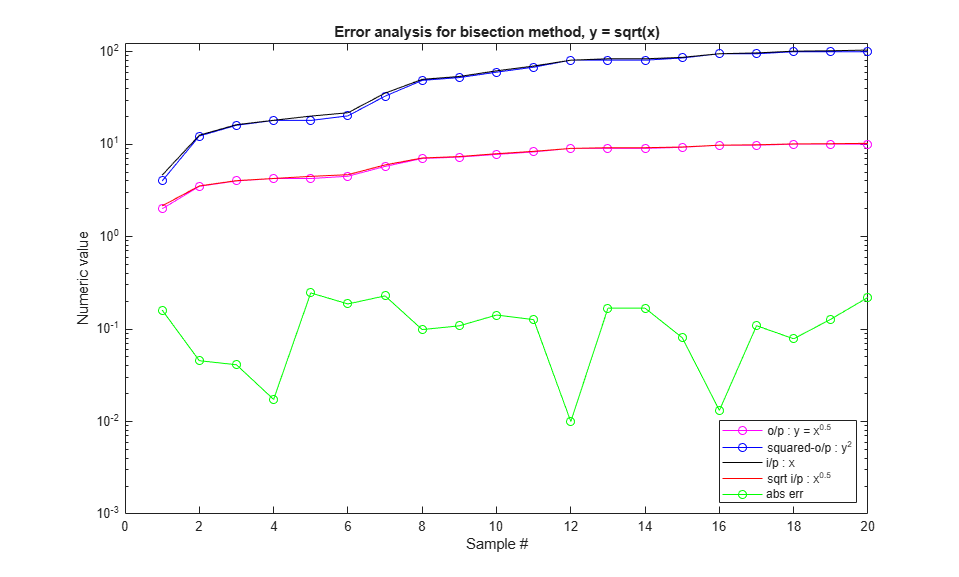
Iter = 01| Input = 0.000| Output = 0000000000 (0.00) | actual = 0.000000 | abserror = 0.000000 Iter = 02| Input = 0.000| Output = 0000000000 (0.00) | actual = 0.000000 | abserror = 0.000000 Iter = 03| Input = 0.000| Output = 0000000000 (0.00) | actual = 0.000000 | abserror = 0.000000 Iter = 04| Input = 0.000| Output = 0000000000 (0.00) | actual = 0.000000 | abserror = 0.000000 Iter = 05| Input = 0.000| Output = 0000000000 (0.00) | actual = 0.000000 | abserror = 0.000000 Iter = 06| Input = 0.000| Output = 0000000000 (0.00) | actual = 0.000000 | abserror = 0.000000 Iter = 07| Input = 0.000| Output = 0000000000 (0.00) | actual = 0.000000 | abserror = 0.000000 Iter = 08| Input = 0.000| Output = 0000000000 (0.00) | actual = 0.000000 | abserror = 0.000000 Iter = 09| Input = 0.000| Output = 0000000000 (0.00) | actual = 0.000000 | abserror = 0.000000 Iter = 10| Input = 0.000| Output = 0000000000 (0.00) | actual = 0.000000 | abserror = 0.000000 Iter = 11| Input = 4.625| Output = 0000010000 (2.00) | actual = 2.150581 | abserror = 0.150581 Iter = 12| Input = 12.500| Output = 0000011100 (3.50) | actual = 3.535534 | abserror = 0.035534 Iter = 13| Input = 16.250| Output = 0000100000 (4.00) | actual = 4.031129 | abserror = 0.031129 Iter = 14| Input = 18.125| Output = 0000100010 (4.25) | actual = 4.257347 | abserror = 0.007347 Iter = 15| Input = 20.125| Output = 0000100010 (4.25) | actual = 4.486090 | abserror = 0.236090 Iter = 16| Input = 21.875| Output = 0000100100 (4.50) | actual = 4.677072 | abserror = 0.177072 Iter = 17| Input = 35.625| Output = 0000101110 (5.75) | actual = 5.968668 | abserror = 0.218668 Iter = 18| Input = 50.250| Output = 0000111000 (7.00) | actual = 7.088723 | abserror = 0.088723 Iter = 19| Input = 54.000| Output = 0000111010 (7.25) | actual = 7.348469 | abserror = 0.098469 Iter = 20| Input = 62.125| Output = 0000111110 (7.75) | actual = 7.881941 | abserror = 0.131941 Iter = 21| Input = 70.000| Output = 0001000010 (8.25) | actual = 8.366600 | abserror = 0.116600 Iter = 22| Input = 81.000| Output = 0001001000 (9.00) | actual = 9.000000 | abserror = 0.000000 Iter = 23| Input = 83.875| Output = 0001001000 (9.00) | actual = 9.158330 | abserror = 0.158330 Iter = 24| Input = 83.875| Output = 0001001000 (9.00) | actual = 9.158330 | abserror = 0.158330 Iter = 25| Input = 86.875| Output = 0001001010 (9.25) | actual = 9.320676 | abserror = 0.070676 Iter = 26| Input = 95.125| Output = 0001001110 (9.75) | actual = 9.753205 | abserror = 0.003205 Iter = 27| Input = 97.000| Output = 0001001110 (9.75) | actual = 9.848858 | abserror = 0.098858 Iter = 28| Input = 101.375| Output = 0001010000 (10.00) | actual = 10.068515 | abserror = 0.068515 Iter = 29| Input = 102.375| Output = 0001010000 (10.00) | actual = 10.118053 | abserror = 0.118053 Iter = 30| Input = 104.250| Output = 0001010000 (10.00) | actual = 10.210289 | abserror = 0.210289
Create a New HDL Coder Project
coder -hdlcoder -new mlhdlc_sqrt_prj
Next, add the file mlhdlc_sqrt.m to the project as the MATLAB Function and mlhdlc_sqrt_tb.m as the MATLAB Test Bench.
For a more complete tutorial on creating and populating MATLAB HDL Coder projects, see Generate HDL Code from MATLAB Algorithms.
Run HDL Code Generation
This design is already in fixed point and suitable for HDL code generation. It is not desirable to run floating point to fixed point advisor on this design.
Click the Workflow Advisor button to start the HDL Workflow Advisor.
In the HDL Workflow Advisor task, set Fixed-point conversion to
Keep original types.In the HDL Code Generation task, select the Optimizations tab.
Clear the MAP persistent array variables to RAMs checkbox. Clearing this option prevents the pipeline from being inferred as RAM.
Additionally, you can select Distribute pipeline registers, set Resource sharing factor to the
wordlength(10 here), and select Stream Loops.Right-click on the HDL Code Generation task and click Run This Task.
Examine the generated HDL code by clicking on the hyperlinks in the Code Generation Log window.
Examine the Synthesis Results
Run the logic synthesis step with the following default options if you have ISE installed on your machine.
In the synthesis report, note the clock frequency reported by the synthesis tool without any optimization options enabled.
Typically the timing performance of this design, using Xilinx® ISE synthesis tool for the
Virtex7chip family, devicexc7v285t, speed grade-3, is around229MHzwith a maximum combinatorial path delay of0.406ns.Optimizations for this design (loop streaming and multiplier sharing) work to reduce resource usage, with a moderate tradeoff on timing. For the particular word-length size in test bench you see a reduction of
nmultipliers to one.