Automatically Schedule for-Loops for Neighborhood Processing Subsystems
Code generated from Neighborhood Processing Subsystem, Pixel Processing Subsystem, and Array Processing Subsystem blocks contain for-loop nests, which can be computationally expensive. You can generate efficient nested loop code using automatic scheduling. Automatically scheduling loop nests can significantly improve the execution speed of the generated code.
When you enable automatic scheduling, the code generator determines the optimal sequence of transformations for a loop nest created from a subsystem block. Depending on factors such as input size, data type, and layout, as well as memory access patterns and other computations, loop transformations might or might not enhance performance. The code generator evaluates the impact of these factors in terms of parallelization and cache performance to determine which loop transformations, if any, are executed. Typically, speedup occurs when the size of the input to the block is sufficiently large. Consequently, automatically scheduling is useful for high-throughput applications such as image processing and computer vision.
This example shows how to automatically schedule for-loops in the generated code of a Neighborhood Processing Subsystem block that sums elements of a large matrix.
Configure a Neighborhood Processing Subsystem Block to Sum Elements of a Matrix
Configure a Neighborhood Processing Subsystem block to return a matrix whose elements are the sum of the 3-by-3 neighborhood surrounding each input element.
1. Create or open a model that contains a Neighborhood Processing Subsystem block.
model = 'AutomaticallyScheduleForLoops';
open_system(model);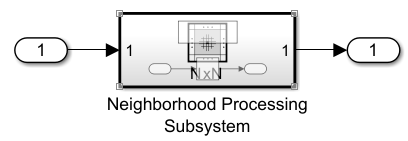
2. Inside the Neighborhood Processing Subsystem block, insert a Sum of Elements block between input and output.
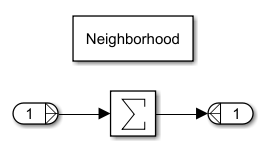
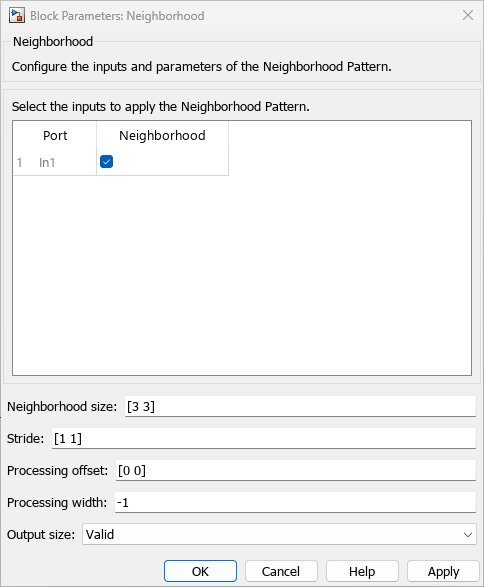
3. In the Block Parameters: Neighborhood dialog box:
Set Neighborhood Size to
[3 3].Set Output Size to
Valid.
4. In the top model, connect an Inport block and Outport block to the Neighborhood Processing Subsystem block.
5. Open the Block Parameters dialog box for the Inport block. In the Signal Attributes tab, set Port Dimensions to [2000 2000]. The input to the Neighborhood Processing Subsystem block is sufficiently large for the automatic scheduler to transform loop nests.
Generate Code Using Default Parameters
1. Open the Configuration Parameters dialog box. In the Code Generation pane, set the System Target File parameter to ert.tlc.
set_param(model,SystemTargetFile='ert.tlc');2. Build the model and generate code.
slbuild(model);
### Searching for referenced models in model 'AutomaticallyScheduleForLoops'. ### Total of 1 models to build. ### Starting build procedure for: AutomaticallyScheduleForLoops ### Successful completion of build procedure for: AutomaticallyScheduleForLoops Build Summary Top model targets: Model Build Reason Status Build Duration ================================================================================================================================ AutomaticallyScheduleForLoops Information cache folder or artifacts were missing. Code generated and compiled. 0h 0m 7.9749s 1 of 1 models built (0 models already up to date) Build duration: 0h 0m 8.5996s
If you do not select the Automatically schedule for-loops parameter, the code generator produces the following nested loop code.
cfile = fullfile('AutomaticallyScheduleForLoops_ert_rtw','AutomaticallyScheduleForLoops.c'); coder.example.extractLines(cfile,'/* Model step function */', '/* Model initialize function */', 1, 0);
/* Model step function */
void AutomaticallyScheduleForLoops_step(void)
{
real_T Img_Load[9];
real_T rtb_SumofElements_0;
int32_T i;
int32_T var1;
int32_T var2;
for (var1 = 0; var1 < 1998; var1++) {
for (var2 = 0; var2 < 1998; var2++) {
/* Inport: '<Root>/Inport' */
Img_Load[0] = AutomaticallyScheduleForLoops_U.Inport[2000 * var2 + var1];
Img_Load[3] = AutomaticallyScheduleForLoops_U.Inport[(var2 + 1) * 2000 +
var1];
Img_Load[6] = AutomaticallyScheduleForLoops_U.Inport[(var2 + 2) * 2000 +
var1];
Img_Load[1] = AutomaticallyScheduleForLoops_U.Inport[(2000 * var2 + var1)
+ 1];
Img_Load[4] = AutomaticallyScheduleForLoops_U.Inport[((var2 + 1) * 2000 +
var1) + 1];
Img_Load[7] = AutomaticallyScheduleForLoops_U.Inport[((var2 + 2) * 2000 +
var1) + 1];
Img_Load[2] = AutomaticallyScheduleForLoops_U.Inport[(2000 * var2 + var1)
+ 2];
Img_Load[5] = AutomaticallyScheduleForLoops_U.Inport[((var2 + 1) * 2000 +
var1) + 2];
Img_Load[8] = AutomaticallyScheduleForLoops_U.Inport[((var2 + 2) * 2000 +
var1) + 2];
/* Outputs for Iterator SubSystem: '<Root>/Neighborhood Processing Subsystem' */
/* Sum: '<S1>/Sum of Elements' */
rtb_SumofElements_0 = 0.0;
for (i = 0; i < 9; i++) {
rtb_SumofElements_0 += Img_Load[i];
}
/* EVCGNDSliceAssignment generated from: '<S1>/Outport' incorporates:
* Sum: '<S1>/Sum of Elements'
*/
AutomaticallyScheduleForLoops_Y.Outport[var1 + 1998 * var2] =
rtb_SumofElements_0;
/* End of Outputs for SubSystem: '<Root>/Neighborhood Processing Subsystem' */
}
}
}
Generate Code Using Automatic Scheduling
To transform the above for-loop nest, the code generator employs the optimization technique of parallelization. You must therefore enable parallel for-loops before running automatic scheduling.
1. In the Optimization pane, set Specify custom optimizations to on.
set_param(model,OptimizationCustomize='on');Then set both Generate parallel for-loops and Automatically schedule for-loops to on.
set_param(model,MultiThreadedLoops='on'); set_param(model,AutoScheduleForLoops='on');
Doing so enables you to generate nested loop code using automatic scheduling.
2. Build the model and generate code.
slbuild(model);
### Searching for referenced models in model 'AutomaticallyScheduleForLoops'. ### Total of 1 models to build. ### Starting build procedure for: AutomaticallyScheduleForLoops ### Successful completion of build procedure for: AutomaticallyScheduleForLoops Build Summary Top model targets: Model Build Reason Status Build Duration ============================================================================================================ AutomaticallyScheduleForLoops Generated code was out of date. Code generated and compiled. 0h 0m 5.8209s 1 of 1 models built (0 models already up to date) Build duration: 0h 0m 6.4588s
The code generator produces the following nested loop code. By parallelizing the outer of the two loops over the blocks, the resulting code is optimized for the large input size.
cfile = fullfile('AutomaticallyScheduleForLoops_ert_rtw','AutomaticallyScheduleForLoops.c'); coder.example.extractLines(cfile,'/* Model step function */', '/* Model initialize function */', 1, 0);
/* Model step function */
void AutomaticallyScheduleForLoops_step(void)
{
const real_T (*Inport)[4000000];
real_T (*rtb_ImpAsg_InsertedFor_Outpor_0)[3992004];
real_T Img_Load[9];
real_T rtb_SumofElements_0;
int32_T i;
int32_T var1;
int32_T var2;
/* Inport: '<Root>/Inport' */
Inport = &AutomaticallyScheduleForLoops_U.Inport;
/* Outputs for Iterator SubSystem: '<Root>/Neighborhood Processing Subsystem' */
/* EVCGNDSliceAssignment generated from: '<S1>/Outport' */
rtb_ImpAsg_InsertedFor_Outpor_0 = &AutomaticallyScheduleForLoops_Y.Outport;
/* End of Outputs for SubSystem: '<Root>/Neighborhood Processing Subsystem' */
#pragma omp parallel for num_threads(omp_get_max_threads()) private(var1,Img_Load,rtb_SumofElements_0,i)
for (var2 = 0; var2 < 1998; var2++) {
for (var1 = 0; var1 < 1998; var1++) {
Img_Load[0] = (*Inport)[2000 * var2 + var1];
Img_Load[3] = (*Inport)[(var2 + 1) * 2000 + var1];
Img_Load[6] = (*Inport)[(var2 + 2) * 2000 + var1];
Img_Load[1] = (*Inport)[(2000 * var2 + var1) + 1];
Img_Load[4] = (*Inport)[((var2 + 1) * 2000 + var1) + 1];
Img_Load[7] = (*Inport)[((var2 + 2) * 2000 + var1) + 1];
Img_Load[2] = (*Inport)[(2000 * var2 + var1) + 2];
Img_Load[5] = (*Inport)[((var2 + 1) * 2000 + var1) + 2];
Img_Load[8] = (*Inport)[((var2 + 2) * 2000 + var1) + 2];
/* Outputs for Iterator SubSystem: '<Root>/Neighborhood Processing Subsystem' */
/* Sum: '<S1>/Sum of Elements' */
rtb_SumofElements_0 = 0.0;
for (i = 0; i < 9; i++) {
rtb_SumofElements_0 += Img_Load[i];
}
(*rtb_ImpAsg_InsertedFor_Outpor_0)[var1 + 1998 * var2] =
rtb_SumofElements_0;
/* End of Sum: '<S1>/Sum of Elements' */
/* End of Outputs for SubSystem: '<Root>/Neighborhood Processing Subsystem' */
}
}
}
See Also
Automatically schedule for-loops | Neighborhood Processing Subsystem