Multilayer Shallow Neural Network Architecture
This topic presents part of a typical multilayer shallow network workflow. For more information and other steps, see Multilayer Shallow Neural Networks and Backpropagation Training.
Neuron Model (logsig, tansig, purelin)
An elementary neuron with R inputs is shown below. Each input is weighted with an appropriate w. The sum of the weighted inputs and the bias forms the input to the transfer function f. Neurons can use any differentiable transfer function f to generate their output.

Multilayer networks often use the log-sigmoid transfer function logsig.

The function logsig generates outputs between 0 and 1
as the neuron's net input goes from negative to positive infinity.
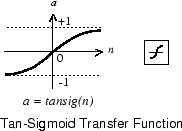
Alternatively, multilayer networks can use the tan-sigmoid transfer function tansig.
Sigmoid output neurons are often used for pattern recognition problems, while linear
output neurons are used for function fitting problems. The linear transfer function
purelin is shown below.

The three transfer functions described here are the most commonly used transfer functions for multilayer networks, but other differentiable transfer functions can be created and used if desired.
Feedforward Neural Network
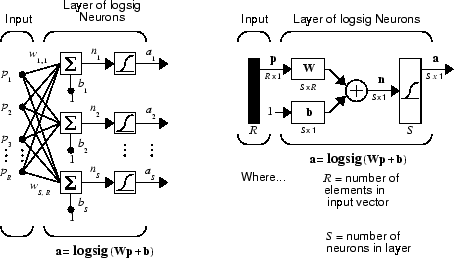
A single-layer network of S
logsig neurons having R
inputs is shown below in full detail on the left and with a layer diagram on the right.
Feedforward networks often have one or more hidden layers of sigmoid neurons followed by an output layer of linear neurons. Multiple layers of neurons with nonlinear transfer functions allow the network to learn nonlinear relationships between input and output vectors. The linear output layer is most often used for function fitting (or nonlinear regression) problems.
On the other hand, if you want to constrain the outputs of a network (such as between
0 and 1), then the output layer should use a sigmoid transfer function (such as
logsig). This is the case when the network
is used for pattern recognition problems (in which a decision is being made by the
network).
For multiple-layer networks the layer number determines the superscript on the weight
matrix. The appropriate notation is used in the two-layer tansig/purelin network shown next.
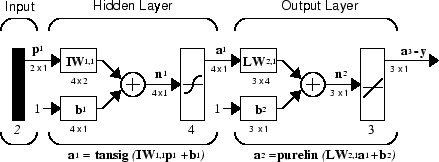
This network can be used as a general function approximator. It can approximate any function with a finite number of discontinuities arbitrarily well, given sufficient neurons in the hidden layer.
Now that the architecture of the multilayer network has been defined, the design process is described in the following sections.