Classify Image Using GoogLeNet
This example shows how to classify an image using the pretrained deep convolutional neural network GoogLeNet.
GoogLeNet has been trained on over a million images and can classify images into 1000 object categories (such as keyboard, coffee mug, pencil, and many animals). The network has learned rich feature representations for a wide range of images. The network takes an image as input, and then outputs a label for the object in the image together with the probabilities for each of the object categories.
Load Pretrained Network
Load the pretrained GoogLeNet network and the corresponding class names using the imagePretrainedNetwork function. This step requires the Deep Learning Toolbox™ Model for GoogLeNet Network support package. If you do not have the required support packages installed, then the software provides a download link.
You can also choose to load a different pretrained network for image classification. To try a different pretrained network, open this example in MATLAB® and select a different network. For example, you can try SqueezeNet, a network that is even faster than GoogLeNet. You can run this example with other pretrained networks. For a list of all available networks, see Pretrained Deep Neural Networks.
[net,classNames] = imagePretrainedNetwork( "googlenet");
"googlenet");The image that you want to classify must have the same size as the input size of the network. For GoogLeNet, the first element of the Layers property of the network is the image input layer. The network input size is the InputSize property of the image input layer.
inputSize = net.Layers(1).InputSize
inputSize = 1×3
224 224 3
View 10 of the class names at random.
numClasses = numel(classNames); disp(classNames(randperm(numClasses,10)))
"hartebeest"
"streetcar"
"hair slide"
"entertainment center"
"wreck"
"Siamese cat"
"racket"
"purse"
"marmoset"
"fountain"
Read Image
Read and show the image that you want to classify.
I = imread("peppers.png");
figure
imshow(I)
Resize and Classify Image
Display the size of the image. The image is 384-by-512 pixels and has three color channels (RGB).
size(I)
ans = 1×3
384 512 3
Resize the image to the input size of the network by using imresize. This resizing slightly changes the aspect ratio of the image.
X = imresize(I,inputSize(1:2)); figure imshow(X)

Depending on your application, you might want to resize the image in a different way. For example, you can crop the top left corner of the image by using I(1:inputSize(1),1:inputSize(2),:). If you have Image Processing Toolbox™, then you can use the imcrop function.
Use the neural network to make a prediction. To make a prediction with a single image, use the predict function. The image has datatype uint8. To make predictions with the neural network, convert the image to data type single. To use a GPU, convert the data to gpuArray. Using a GPU requires a Parallel Computing Toolbox™ license and a supported GPU device. For information on supported devices, see GPU Computing Requirements (Parallel Computing Toolbox). Otherwise, the function uses the CPU.
X = single(X); if canUseGPU X = gpuArray(X); end scores = predict(net,X);
The predict function returns the probabilities for each class. To convert the classification scores to a categorical label, use the scores2label function.
[label,score] = scores2label(scores,classNames);
Display the original image with the predicted label and the predicted probability of the image having that label.
figure
imshow(I)
title(string(label) + ", " + score)
Display Top Predictions
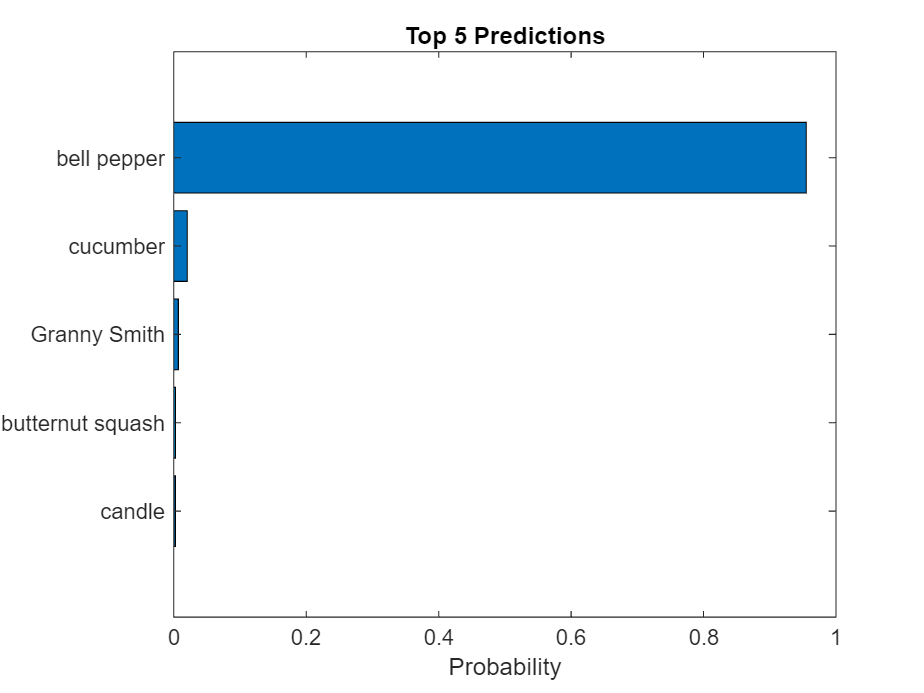
Display the top five predicted labels and their associated probabilities as a histogram. Because the network classifies images into so many object categories, and many categories are similar, it is common to consider the top-five accuracy when evaluating networks. The network classifies the image as a bell pepper with a high probability.
[~,idx] = sort(scores,"descend"); idx = idx(5:-1:1); classNamesTop = classNames(idx); scoresTop = scores(idx); figure barh(scoresTop) xlim([0 1]) title("Top 5 Predictions") xlabel("Probability") yticklabels(classNamesTop)
References
[1] Szegedy, Christian, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. "Going deeper with convolutions." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1-9. 2015.
[2] BVLC GoogLeNet Model. https://github.com/BVLC/caffe/tree/master/models/bvlc_googlenet
See Also
imagePretrainedNetwork | dlnetwork | trainingOptions | trainnet | minibatchpredict | scores2label | predict
Related Topics
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)